¿Qué encontraremos en este artículo?
El muro invisible entre la eficiencia y tú
Dominar la IA generativa se ha vuelto el requisito indispensable en estos tiempos, para no sentirse perdido en foros de negocios o conferencias virtuales. Seguramente te ha pasado: escuchas términos como «pesos», «ventana de contexto» o «latencia de inferencia» y sientes que descifras un idioma ajeno. Como profesional o emprendedor, esa sensación de estar «fuera de la onda» no es solo frustrante; es peligrosa para tu competitividad en el mercado actual.
El problema es real: la tecnología avanza a pasos agigantados, pero la terminología se queda atrapada en tecnicismos de laboratorio que no parecen tener conexión con tu día a día. Si no comprendes los conceptos básicos, no puedes dar instrucciones precisas. Si no das instrucciones precisas, los resultados de tus herramientas son mediocres. Y en la economía de la atención, lo mediocre es invisible.
La buena noticia es que no necesitas ser ingeniero para dominar la IA generativa, al menos en lo que respecta a su vocabulario. En este artículo, vamos a derribar ese muro. Hemos preparado para ti el glosario más exhaustivo y práctico del mercado, diseñado para que pases de la confusión a la maestría. Vamos a traducir el lenguaje de las máquinas al lenguaje de los resultados.
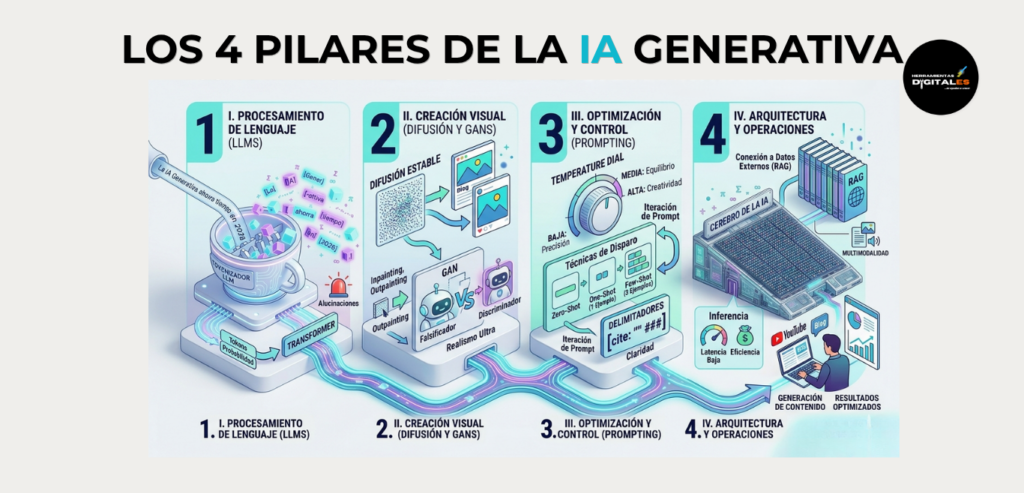
Guía de navegación: Los 4 pilares de la IA Generativa
Antes de sumergirnos en las definiciones, es vital entender el ecosistema. Este glosario está estructurado en cuatro dimensiones estratégicas que te permitirán dominar la tecnología desde la base hasta la ejecución profesional:
El mapa del glosario (Las 4 dimensiones)
| Bloque | Nombre del Pilar | ¿Qué aprenderá el lector aquí? |
| I | Procesamiento de Lenguaje (LLMs) | El mundo del texto: Cómo la IA lee, escribe, cuenta (tokens) y por qué a veces miente (alucinaciones). |
| II | Generación Visual (Difusión y GANs) | El mundo de las imágenes: Cómo se crean desde cero, cómo se editan por dentro (inpainting) o se expanden (outpainting). |
| III | Optimización y Control (Prompting) | El manejo: Cómo darle órdenes a la IA para que sea creativa o técnica (temperatura) y precisa. |
| IV | Arquitectura y Operaciones | La ingeniería: Qué hay bajo el capó (parámetros), cómo piensa (transformers) y cómo usa varios sentidos a la vez (multimodalidad). |
I- Procesamiento de lenguaje y texto
Esta es la columna vertebral de la revolución actual. En esta sección, exploramos cómo las máquinas han pasado de simplemente ‘leer’ código a comprender y generar lenguaje humano con una fluidez asombrosa. Entender los modelos de lenguaje de gran escala (LLM) es comprender cómo la IA procesa la información, estructura el pensamiento lógico y se comunica con nosotros. Aquí descifraremos los conceptos que permiten que una máquina no solo escriba, sino que razone.
LLM (Large Language Models)
Los Modelos de Lenguaje de Gran Tamaño son la columna vertebral de la revolución actual. Se trata de sistemas entrenados con volúmenes masivos de datos textuales para comprender, resumir, generar y predecir contenido. En el contexto actual, nombres como Gemini de Google o GPT-4 son los referentes. Su importancia radica en que no solo «escriben»; son capaces de razonar lógicamente sobre problemas complejos.
Para profundizar en los LLM sin perdernos en un laberinto técnico, es fundamental entender que no son bases de datos que «buscan» información, sino motores probabilísticos de predicción.
Aquí tienes tres pilares que explican por qué estos modelos han cambiado las reglas del juego en el ecosistema digital:
1. La Arquitectura Transformer (El «Cerebro»)
A diferencia de las IAs antiguas que leían una oración palabra por palabra (de izquierda a derecha), los LLM modernos utilizan una arquitectura llamada Transformer.
Mecanismo de atención: Esto permite que el modelo «mire» toda la oración (o el documento) al mismo tiempo. Entiende que en la frase «El banco estaba sucio, así que lo limpié», la palabra «banco» se refiere a un mueble y no a una entidad financiera, gracias al contexto de «limpié».
Procesamiento en paralelo: Gracias a esto, pueden entrenarse con casi todo el texto disponible en internet en tiempos récord.
Nota: En el Bloque IV desglosaremos la ingeniería técnica de este ‘cerebro’ a fondo.
2. El Entrenamiento: De la predicción al conocimiento
Un LLM aprende mediante un juego de «completar la frase». Se le ocultan palabras de un texto y el modelo debe adivinar cuál sigue.
Probabilidad pura: Cuando le pides que escriba un artículo, el modelo calcula cuál es el token (fragmento de palabra) que tiene mayor probabilidad de aparecer después del anterior, basándose en los billones de ejemplos que leyó.
Emergencia de razonamiento: Al escalar estos modelos a miles de millones de parámetros (ajustes internos), los científicos descubrieron que la IA empezaba a «razonar» por sí misma, resolviendo problemas de lógica o programación que nadie le enseñó explícitamente.
3. La Ventana de contexto (La «Memoria de Trabajo»)
Si el entrenamiento es lo que la IA «sabe», la ventana de contexto es lo que la IA «está viendo» en este momento. Es el espacio limitado de datos que el modelo puede procesar en una sola sesión.
Memoria volátil: Todo lo que escribes en un chat se guarda en esta ventana. Es lo que permite que la IA recuerde lo que dijiste diez párrafos arriba.
El límite del enfoque: Cada modelo tiene un límite (medido en tokens). Si el chat es demasiado largo y excede la ventana, la IA empieza a «olvidar» el inicio de la conversación.
El riesgo del «olvido selectivo»
Si pegas un libro de 500 páginas y el modelo solo tiene una ventana de 32,000 tokens, la IA sufrirá un desbordamiento: olvidará el inicio antes de llegar al final. Técnicamente, cuando se supera este límite, los tokens más antiguos son expulsados del «recuerdo» activo de la IA para dar paso a los nuevos, lo que provoca que el modelo pierda el hilo de tus instrucciones iniciales o ignore datos cruciales del principio del documento.
Jerarquía de atención (Lost in the Middle)
Estudios en ingeniería de prompts han demostrado un fenómeno curioso: incluso si un modelo tiene una ventana de contexto grande, a veces tiende a recordar mejor la información al principio y al final del contexto, perdiendo precisión en los datos ubicados en el medio. Para un estratega de contenido, esto significa que la información vital de un prompt debe colocarse estratégicamente en los extremos para maximizar la «atención» de la IA.
La revolución de los millones de tokens
Actualmente, modelos de alto rendimiento (como Gemini 1.5 Pro) ya manejan ventanas de millones de tokens de contexto (hasta 2 millones o más). Esto ha cambiado las reglas del juego para los negocios digitales, permitiendo tareas que antes eran imposibles:

Análisis masivo: Subir horas de video, miles de líneas de código o bases de datos completas en un solo prompt.
Consistencia global: La IA puede redactar el capítulo 10 de un curso online recordando exactamente qué tono y ejemplos usó en el capítulo 1, garantizando una uniformidad perfecta.
¿Qué puede hacer un LLM por ti?
| Capacidad | Descripción Práctica |
| In-context Learning | La habilidad de aprender una tarea mediante ejemplos inmediatos (ver sección ‘Estrategias de Disparo’ en el Bloque III), sin necesidad de reprogramarla |
| Síntesis Semántica | Puede leer un reporte de 50 páginas y extraer los 3 puntos clave que afectan a tu industria en segundos. |
| Generación de Código | Actúa como un traductor entre el lenguaje humano y el lenguaje de las máquinas (Python, HTML, etc.), acelerando el desarrollo técnico. |
El dato crítico: El «Límite de conocimiento»
A diferencia de un buscador, un LLM estándar tiene una fecha de corte. Si el modelo terminó su entrenamiento en 2025, no «sabe» qué pasó esta mañana a menos que use herramientas de búsqueda en tiempo real o RAG (conexión a datos externos). Por eso, su mayor valor no es ser una enciclopedia, sino un procesador de ideas.
Nota de valor: Entender que un LLM es un «predictor de texto sofisticado» te ayuda a dejar de confiar ciegamente en sus datos (evitando alucinaciones) y empezar a confiar más en su capacidad para estructurar, transformar y dar formato a tu propia información.
Tokens: La unidad atómica y económica de la IA
Si los humanos contamos por palabras, la IA cuenta por tokens. Un token puede ser una palabra completa, un prefijo, un sufijo o incluso un solo signo de puntuación. Es la unidad mínima de procesamiento y la base sobre la cual el modelo construye el significado. Comprender los tokens es vital, no solo por curiosidad técnica, sino porque la mayoría de las plataformas de IA generativa facturan por el volumen de tokens procesados (entrada o input) y generados (salida u output).
Tokenización: El ADN del lenguaje digital
A diferencia de un procesador de textos que ve letras, los LLM utilizan un proceso llamado tokenización. Mediante algoritmos como el Byte-Pair Encoding (BPE), el modelo descompone el lenguaje en fragmentos frecuentes:
Una palabra común como «sol» suele ser 1 token.
Una palabra compleja o técnica como «generativa» podría dividirse en 2 o 3 tokens (ej: «gener-«, «-at», «-iva»).
Los espacios en blanco y los emojis también consumen tokens.

La regla de oro del 75%
Para un usuario digital, la conversión rápida es fundamental para calcular presupuestos. Como norma general en el idioma inglés, 1,000 tokens equivalen aproximadamente a 750 palabras.
Nota para el mercado hispano: En español, debido a nuestra estructura gramatical y el uso de artículos, la relación suele ser un poco más costosa. Por lo general, 1,000 tokens rinden entre 600 y 650 palabras, lo que significa que el procesamiento de contenido en español es, en promedio, un 20% más «caro» en términos de capacidad de ventana que en inglés.
La economía del prompting
En IAs de pago o con planes freemium, optimizar los tokens es optimizar el ROI (Return on Investment o Retorno de la Inversión)
Input vs. Output: Procesar un documento de 50,000 tokens (entrada) para obtener un resumen de 500 (salida) tiene un costo específico.
Eficiencia: El uso de instrucciones claras y directas evita el «ruido de tokens» innecesario, permitiendo que el modelo asigne su capacidad de razonamiento a lo que realmente importa, reduciendo costos operativos en el uso de APIs.
Alucinaciones: El «sueño» de la máquina
Este es, sin duda, uno de los términos más críticos y debatidos en la industria. Una alucinación ocurre cuando la IA genera información que suena coherente, gramaticalmente perfecta y extremadamente segura, pero que es factualmente falsa o no existe en los datos de entrenamiento. El modelo no está «mintiendo», ya que no tiene conciencia de la verdad; simplemente está fallando en su proceso de predicción.
¿Por qué ocurren? El mito de la base de datos
El error más común es creer que la IA es una enciclopedia que «busca» datos. En realidad, las alucinaciones suceden porque los modelos son probabilísticos, no deterministas. Su objetivo fundamental es completar la secuencia de palabras que estadísticamente tiene más sentido, no necesariamente la que es más verdadera. Si el modelo no tiene la respuesta exacta, sus algoritmos de predicción «rellenan los huecos» con información plausible.
Factores que disparan las alucinaciones
Existen tres disparadores principales que un creador de contenido o usuario debe vigilar:
Falta de contexto: Cuando le pides a la IA datos sobre un evento muy reciente (fuera de su fecha de corte) o un nicho demasiado específico del que no tiene datos suficientes.
Temperatura elevada: Como veremos más adelante, una «Temperatura» alta aumenta la creatividad, pero también eleva exponencialmente el riesgo de que la IA se invente datos para sonar más original. Este concepto lo desarrollamos más adelante.
Prompts sugestivos: Si haces una pregunta que asume algo falso (ej: «¿Por qué el cielo es verde en Marte?»), la IA podría intentar complacerte «creando» una explicación técnica para un hecho inexistente.

Tipos de alucinaciones
Intrínsecas: La información contradice directamente el texto fuente que tú le proporcionaste.
Extrínsecas: La información no puede ser verificada con el texto fuente, pero la IA la añade como si fuera un hecho real extraído de su propio conocimiento.
Guía de Supervivencia: Filtros contra la ficción de la IA
Es fundamental entender que esta tendencia de la IA a generar datos inexactos es uno de los puntos críticos de vigilancia para nosotros como usuarios. En lugar de aceptar cada respuesta como una verdad absoluta, debemos adoptar una mentalidad de escepticismo técnico. Para garantizar la integridad de tu contenido, tu misión es implementar los siguientes filtros de seguridad:
Verificación humana: Nunca publiques datos técnicos, fechas o nombres sin una revisión manual.
Uso de RAG (Generación aumentada por recuperación): Al obligar a la IA a leer un documento real antes de responder, reduces la probabilidad de alucinaciones casi a cero, ya que el modelo se limita a los hechos presentes en ese archivo. (este concepto profundizaremos más adelante)
Instrucciones de escape: Incluye en tus prompts la frase: «Si no estás 100% seguro de la respuesta o no encuentras la información, di explícitamente que no lo sabes».
II. Creación visual: El lenguaje de los pixeles
La inteligencia artificial no solo escribe; ahora es capaz de ‘ver’ y crear realidades visuales desde un lienzo en blanco. En este bloque, nos adentramos en la alquimia digital de la generación de imágenes. Veremos cómo la IA transforma descripciones textuales en píxeles y cómo las nuevas arquitecturas permiten a los creadores de contenido editar, expandir y reimaginar el material gráfico con una precisión que antes era exclusiva de estudios de post-producción de alto nivel.
Difusión Estable (Stable Diffusion)
Es una de las arquitecturas más potentes y disruptivas para la creación de imágenes sintéticas. A diferencia de modelos cerrados y centralizados, la Difusión Estable destaca por ser de código abierto, lo que otorga a los creadores soberanía tecnológica al permitirles instalarla en sus propios servidores o estaciones de trabajo locales.
Su funcionamiento se basa en un proceso matemático denominado «eliminación de ruido» (denoising)
Fase de ruido
La IA comienza con un lienzo de estática pura (similar a la nieve de un televisor antiguo sin señal).
Fase de refinamiento
Paso a paso, el modelo predice y elimina el «ruido» innecesario, guiado por tu descripción (prompt), hasta que emerge una imagen nítida que coincide con tu solicitud.
Inpainting y Outpainting: Las herramientas de precisión
Estas funciones representan las «joyas de la corona» para la edición de contenido profesional, permitiendo manipular la realidad digital sin dejar rastro:

Inpainting (edición interna)
Permite seleccionar un área específica dentro de una imagen para que la IA la transforme o repare. Es la herramienta definitiva para el retoque: puedes cambiar el color de una prenda, eliminar un objeto no deseado o modificar la expresión de un rostro, manteniendo la coherencia con el resto de la composición.
Outpainting (extensión de lienzo)
Es la capacidad de «mirar más allá» de los bordes de una imagen original. La IA analiza el estilo, la iluminación y la perspectiva de la foto inicial para generar un paisaje o entorno más amplio que nunca existió, expandiendo la narrativa visual de forma orgánica.
GANs (Redes Generativas Antagónicas)
Las GANs (del inglés Generative Adversarial Networks) representan uno de los hitos más fascinantes de la IA. A diferencia de otros modelos, las GANs no aprenden solas; funcionan mediante un sistema de competencia directa entre dos redes neuronales que «luchan» entre sí en un ciclo infinito de mejora.
Profundidad técnica: El duelo de inteligencias
Este sistema se compone de dos agentes internos con objetivos opuestos:
El Generador: Su misión es crear datos (imágenes, audio, etc.) que parezcan reales. Comienza creando puro ruido, pero aprende de sus errores.
El Discriminador: Actúa como un juez o detective. Su trabajo es analizar lo que el Generador produce y compararlo con datos reales para determinar si es «auténtico» o «falso».
El «antagonismo» es la clave: Mientras el detective se vuelve mejor detectando falsificaciones, el falsificador se ve obligado a volverse más brillante para engañarlo. Al final de este entrenamiento, el Generador es capaz de crear contenido con un nivel de detalle que, a menudo, es indistinguible de la realidad para el ojo humano.
Ejemplo práctico: El Falsificador de arte digital
Imagina que quieres que la IA aprenda a crear retratos de personas que NO existen:
Ronda 1: El Generador entrega un cuadro lleno de manchas borrosas. El Discriminador lo mira, lo compara con fotos reales y dice: «Falso. Esto no tiene ojos ni piel».
Ronda 1,000: El Generador ya dibuja rostros, pero quizás con tres ojos. El Discriminador dice: «Falso. Los humanos solo tienen dos ojos».
Ronda 1,000,000: El Generador crea un rostro con poros en la piel, reflejos en las pupilas y cabello realista. El Discriminador ya no puede notar la diferencia y admite la imagen como real.
La evolución del realismo
Las GANs marcaron el inicio de la era del ultra-realismo digital. Aunque hoy convivimos con modelos de difusión más versátiles, entender el «antagonismo» entre redes nos permite comprender por qué la IA es capaz de auto-corregirse y alcanzar niveles de detalle asombrosos.
Como usuario, reconocer estas arquitecturas te da el criterio necesario para elegir la herramienta correcta: usa GANs cuando busques realismo fotográfico humano absoluto y modelos de Difusión cuando necesites creatividad, composición y control total sobre el escenario.
Latent Space (Espacio Latente)
El Espacio Latente es, en esencia, el «universo matemático» comprimido donde la IA organiza y almacena todas las posibilidades de una imagen o concepto que ha aprendido durante su entrenamiento. No es una galería de fotos, sino una representación multidimensional de características. Cuando escribes un prompt, no estás pidiendo una búsqueda en una base de datos; estás dando coordenadas específicas a la IA para que se desplace por ese mapa matemático, localice los conceptos que imaginas y los materialice.
Profundidad técnica: El mapa de los conceptos
Para visualizarlo, imagina un mapa donde en un extremo está el concepto «perro» y en el otro «astronauta». El espacio entre ellos no está vacío; contiene todas las variaciones posibles.
Dimensiones: Mientras que nosotros vivimos en 3 dimensiones, el espacio latente de una IA puede tener cientos o miles de dimensiones. Cada dimensión representa un rasgo (color, textura, forma, estilo).

Compresión inteligente: La IA comprime información masiva para quedarse solo con lo esencial. No guarda cada píxel de un «gato», guarda la esencia matemática de lo que hace que un gato parezca un gato.
Navegación semántica: Si pides un «perro astronauta», la IA calcula la intersección matemática entre esos dos puntos del mapa y genera una imagen que fusiona ambos conceptos de forma coherente.
Ejemplo práctico: El GPS de la imaginación
Imagina que el espacio latente es un océano infinito:
1. Tu Prompt es el GPS. Al escribir «Atardecer ochentero en una ciudad futurista», le das a la IA el punto exacto de longitud y latitud en ese océano.
2. La IA viaja a esa ubicación donde se cruzan los vectores de «luces de neón», «arquitectura de ciencia ficción» y «colores cálidos de puesta de sol».
3. Al llegar, «pesca» la información de ese punto y la traduce en los píxeles que ves en tu pantalla.
La cartografía de la creación
Dominar el Espacio Latente es entender que la IA es una cartógrafa de ideas. No crea de la nada; descubre combinaciones dentro de un universo de posibilidades que ya ha mapeado. Para el usuario de IA, esto significa que el límite de la herramienta no es su capacidad de dibujo, sino nuestra capacidad para navegar su mapa matemático a través del lenguaje.
III. Optimización y control: El arte del prompting
Tener el motor más potente del mundo no sirve de nada si no sabes cómo conducirlo. Esta sección es el puente entre la capacidad de la IA y tu visión creativa. Aquí exploramos la ‘Ingeniería de Instrucciones’ o Prompt Engineering: el conjunto de técnicas, parámetros y estrategias que te permiten tomar el mando absoluto del sistema. Aprenderás que la diferencia entre un resultado mediocre y uno brillante no está en la IA, sino en la claridad y estructura de tus órdenes.
Prompt Engineering: El arte de programar con palabras
La Ingeniería de Instrucciones (o Prompt Engineering) ha dejado de ser un simple «truco» para convertirse en una de las disciplinas más críticas de la era de la IA. No se trata solo de escribir frases; es la ciencia de diseñar entradas de datos que guíen a los modelos de lenguaje (LLM) para que entreguen resultados de alta precisión, minimizando errores y sesgos.
1. Los componentes de un prompt perfecto
Para que una instrucción sea efectiva, un ingeniero de prompts profesional utiliza una estructura que suele incluir cuatro elementos clave:
Rol (Persona): Define quién es la IA (ej. «Actúa como un experto en SEO»).
Contexto: Entrega los antecedentes (ej. «Estamos escribiendo para un blog de tecnología en Perú»).
Tarea: La acción clara y directa (ej. «Redacta un glosario de 10 términos»).
Restricciones y formato: Define lo que no quieres y cómo debe verse el resultado (ej. «No uses tecnicismos, entrégalo en una tabla Markdown»).
2. Técnicas de control avanzado
El Prompt Engineering utiliza estrategias lógicas para mejorar el razonamiento de la máquina:
Iteración semántica: No se acepta el primer resultado. Se refina la instrucción basándose en lo que la IA omitió o malinterpretó.
Encadenamiento (Chaining): Dividir una tarea compleja en pasos más pequeños para evitar que la IA pierda el hilo o se abrume.
Uso de delimitadores: Utilizar signos como ### o «»» para que la IA sepa exactamente dónde termina una instrucción y dónde empieza el texto que debe analizar.
3. La importancia de la especificidad
En esta disciplina, la ambigüedad es el enemigo. Un prompt vago genera respuestas genéricas. La ingeniería de instrucciones busca eliminar la incertidumbre dándole a la IA «barandas» lógicas para que no se salga del camino esperado.
Técnicas de Disparo: De la orden directa al ejemplo maestro
Estas técnicas se refieren a la cantidad de ejemplos (o «disparos») que incluyes en tu instrucción para guiar el comportamiento de la IA antes de que genere una respuesta. Dominar estos tres niveles te permite ahorrar tiempo y créditos de generación: mientras un Zero-Shot es rápido, un Few-Shot es profesional y consistente.
1. Zero-Shot (Cero ejemplos)
Es cuando le das una orden directa sin ninguna guía previa. Confías en que el entrenamiento general de la IA ya sabe qué es lo que pides.
Ejemplo: «Traduce este párrafo al inglés: [texto]».
2. One-Shot (Un ejemplo)
Proporcionas un solo ejemplo de cómo quieres que sea el resultado. Es extremadamente útil para definir el formato o el tono de voz de manera rápida.
Ejemplo: «Crea un título para un post. Ejemplo: ‘Cómo optimizar tu PC en 5 pasos’. Ahora haz uno para: [tema]».
3. Few-Shot (Varios ejemplos)
Entregas una pequeña lista de ejemplos (usualmente entre 3 y 5). Es la técnica más potente para tareas complejas, estilos de escritura únicos o clasificaciones de datos difíciles.
Ejemplo: Le das 3 ejemplos de cómo respondes a los comentarios de tu red social o canal de YouTube y luego le pides que responda el cuarto siguiendo ese mismo estilo.
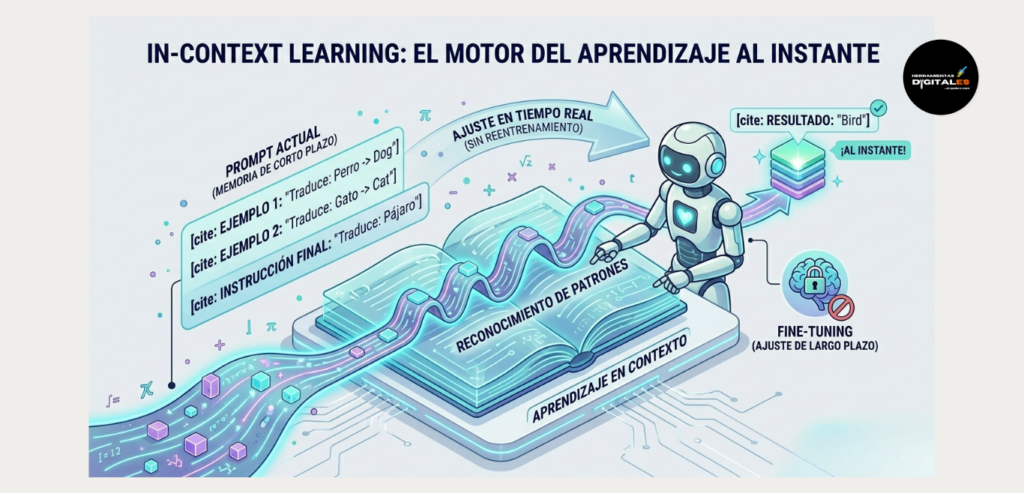
In-Context Learning: El motor del aprendizaje al instante
Para entender por qué los ejemplos anteriores funcionan, debemos conocer el concepto de In-Context Learning (Aprendizaje en Contexto). Es la capacidad de la IA para «aprender» una tarea nueva sobre la marcha, solo leyendo lo que escribes en el chat.
El contexto como guía
A diferencia del Fine-Tuning (que cambia el «cerebro» de la IA de forma permanente), el Few-Shot Prompting funciona aprovechando esta memoria de corto plazo.
Reconocimiento de patrones
La IA no está grabando tus ejemplos para siempre; simplemente usa su «ventana de contexto» para reconocer el patrón matemático de lo que le acabas de mostrar y replicarlo inmediatamente.
Consejo útil: No necesitas ser programador para «entrenar» a la IA; solo necesitas darle buenos ejemplos dentro del prompt para que ella se alinee con tu forma de trabajar en segundos.
Conclusión de la técnica
Dominar estos tres niveles de instrucción te permite ahorrar tiempo y «créditos» de generación. Un Zero-Shot es rápido, pero un Few-Shot es profesional y consistente.
Temperature (Temperatura): El Dial entre la Lógica y la Creatividad
En el mundo de la Inteligencia Artificial, la Temperatura no mide calor, sino probabilidad. Es el parámetro de configuración más potente que tiene un usuario para definir la «personalidad» de la respuesta de un modelo. Entender cómo graduar este dial es lo que diferencia a un usuario casual de un verdadero estratega de contenido.
1. ¿Qué es técnicamente la Temperatura?
Los modelos de IA (LLMs) no eligen palabras, eligen Tokens basándose en estadísticas. Para cada palabra siguiente, la IA tiene una lista de candidatas con diferentes porcentajes de probabilidad. La temperatura es el filtro matemático que altera esa lista:
Temperatura Baja (0.0 a 0.3): El modelo se vuelve «conservador». Elige siempre las opciones con mayor probabilidad estadística. El resultado es coherente, repetitivo y técnico.
Temperatura Alta (0.7 a 1.0 o más): El modelo se vuelve «arriesgado». Empieza a elegir palabras que tienen menor probabilidad, lo que introduce originalidad, sorpresas y, a veces, errores.

2. ¿Cuándo usar cada nivel? (Casos de uso)
Saber configurar la temperatura depende directamente del objetivo de tu tarea en escenario que se usará.
Para datos y hechos (Temp 0.1 – 0.2): Si estás redactando un tutorial sobre cómo sacar el DNI o calcular impuestos en Perú, necesitas precisión absoluta. Una temperatura baja evita que la IA «invente» requisitos o números.
Para redacción estándar (Temp 0.5 – 0.7): Es el punto de equilibrio. Ideal para artículos informativos donde se busca un tono profesional pero fluido, podría aplicarse en la elaboración de artículos.
Para creatividad extrema (Temp 0.8 – 1.0): Si necesitas ideas para títulos virales, guiones de ficción o metáforas originales. Aquí quieres que la IA te sorprenda con conexiones que no son obvias.
3. El riesgo de los extremos
Cerca de 0: La IA puede volverse tan predecible que empieza a buclear (repetir la misma frase una y otra vez).
Por encima de 1: El modelo entra en un estado de «embriaguez digital». Las palabras pierden conexión lógica y las alucinaciones se disparan, generando texto que no tiene sentido.
Consejo útil: Una regla de oro para tu flujo de trabajo: A menor margen de error, menor temperatura. Si el error puede costarte un perjuicio o una desinformación a tu audiencia, mantente cerca del 0. Si el error solo significa un título aburrido que puedes borrar, atrévete a subir a 0.9. Aprender a «setear» la temperatura antes de lanzar un prompt es lo que te ahorrará horas de edición manual.
Iteración de Prompt: El ciclo del refinamiento profesional
En el uso profesional de la IA, el primer resultado casi nunca es el definitivo. La Iteración de Prompt es el proceso estratégico de ajustar, pulir y repetir una instrucción basándose en la respuesta obtenida, hasta lograr que la salida de la IA coincida exactamente con la visión del creador. Es la diferencia entre un «usuario de chat» y un «operador de IA».
1. ¿Por qué es necesaria la iteración?
Los modelos de IA, aunque avanzados, pueden interpretar mal el contexto, usar un tono inadecuado o ser demasiado extensos. La iteración no es una señal de fallo en la IA, sino una parte natural del flujo de trabajo. Al iterar, estamos «calibrando» la respuesta para eliminar la ambigüedad.
2. El método de las tres capas
Un proceso de iteración efectivo suele seguir estos pasos:
Evaluación: Analizar la primera respuesta. ¿Qué faltó? ¿Qué sobró? ¿El tono es el correcto?
Inyección de restricciones: Modificar el prompt añadiendo límites claros (ej. «Mantén el párrafo bajo 50 palabras» o «No menciones marcas específicas»).
Refuerzo de contexto: Darle a la IA más pistas sobre el objetivo final (ej. «Recuerda que este texto es para emprendedores que no saben nada de programación»).
3. La documentación del éxito
La parte más valiosa de la iteración no es solo el resultado final, sino el aprendizaje del camino. Guardar las versiones de los prompts que mejor funcionaron te permite construir tu propia «biblioteca de prompts optimizados», ahorrándote tiempo en proyectos futuros.
Consejo útil: Siempre debemos ver la iteración como el trabajo de un escultor. El primer prompt es el bloque de mármol; las iteraciones son los golpes de cincel que van revelando la figura. No te desesperes si el primer intento es mediocre; el 90% del éxito en la IA Generativa ocurre en la tercera o cuarta iteración. Quien tiene la paciencia para iterar, tiene el poder de crear contenido único.
Delimitadores: Los «muros» lógicos de tu instrucción
En la ingeniería de prompts, la claridad es reina. Los Delimitadores son signos de puntuación o caracteres especiales que se utilizan para separar visual y lógicamente las diferentes partes de un prompt. Su función principal es indicarle a la IA exactamente dónde termina una instrucción y dónde empieza el contenido que debe procesar.
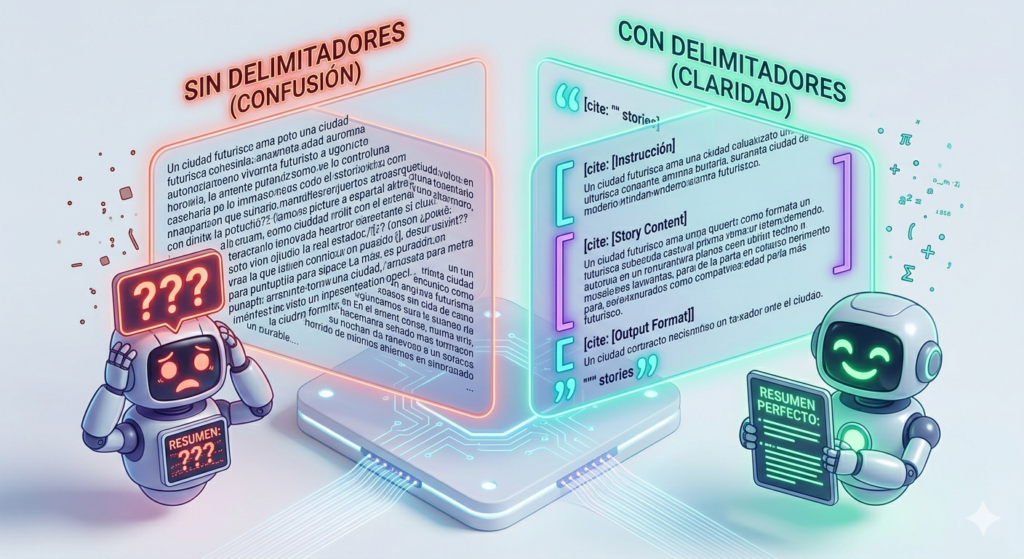
¿Por qué usar delimitadores?
Sin delimitadores, la IA puede sufrir de «Confusión de Instrucción». Por ejemplo, si le pides que resuma un texto que habla sobre «cómo dar órdenes», la IA podría confundirse y creer que el texto es parte de tus instrucciones y no el material a resumir. Los delimitadores eliminan esta ambigüedad creando una frontera clara.
Los delimitadores más comunes
No hay una regla única, pero los más efectivos son:
Triple comilla: «»» Texto «»» (Muy usado para bloques largos de artículos).
Corchetes o llaves: [ Instrucción ] o { Datos }.
Etiquetas tipo HTML: <texto> Contenido </texto> (Excelente para modelos avanzados).
Signos de almohadilla o guiones: ### o — (Ideales para separar secciones).
Ejemplo de un prompt con y sin delimitadores
Incorrecto (Ambigúo): > Traduce este texto a inglés: El usuario debe presionar el botón de inicio.
Correcto (Profesional): Traduce a inglés el texto delimitado por triple comilla.
Texto: «»» El usuario debe presionar el botón de inicio. «»»
Beneficios en la automatización
Cuando usas delimitadores, es mucho más fácil crear plantillas de prompts. Puedes tener una estructura fija y simplemente cambiar el contenido que va dentro de los delimitadores, asegurando que la IA siempre entienda qué parte es la tarea y qué parte es la materia prima.
Consejo útil: En tus flujos de trabajo, acostúmbrate a usar siempre delimitadores. Es como ponerle «vallas» al campo para que la IA no se escape. Esto es especialmente útil cuando procesas textos complejos o técnicos; ayuda a que el modelo mantenga el enfoque y reduce drásticamente los errores de interpretación.
IV. Arquitectura y operaciones
Para el profesional que busca ir un paso más allá, es necesario levantar el capó y observar la ingeniería que sostiene todo el sistema. En este último pilar, analizamos la infraestructura técnica de la IA. Desde cómo se mide el cerebro de estos modelos hasta la capacidad de procesar múltiples sentidos a la vez. Es aquí donde la magia se convierte en matemática y donde entenderás por qué esta tecnología está redefiniendo los límites de lo que es posible en el entorno digital.
RAG: El Antídoto contra las Alucinaciones de la IA
El término RAG (Retrieval-Augmented Generation o Generación Aumentada por Recuperación) describe una técnica que permite a la Inteligencia Artificial consultar fuentes de información externas antes de generar una respuesta. Es, en esencia, darle a la IA un «libro de referencia» abierto para que no tenga que confiar solo en su memoria.
1. ¿Cómo funciona el proceso RAG?
A diferencia de un modelo estándar que responde basándose únicamente en lo que aprendió durante su entrenamiento, un sistema con RAG sigue tres pasos:
Recuperación (Retrieval): Cuando haces una pregunta, el sistema busca en tu base de datos (PDFs, artículos de tu blog, manuales) la información más relevante.
Aumento (Augmentation): El sistema combina tu pregunta original con la información encontrada, creando un «super-prompt» lleno de contexto real.
Generación (Generation): La IA redacta la respuesta final basándose estrictamente en esos datos recuperados.
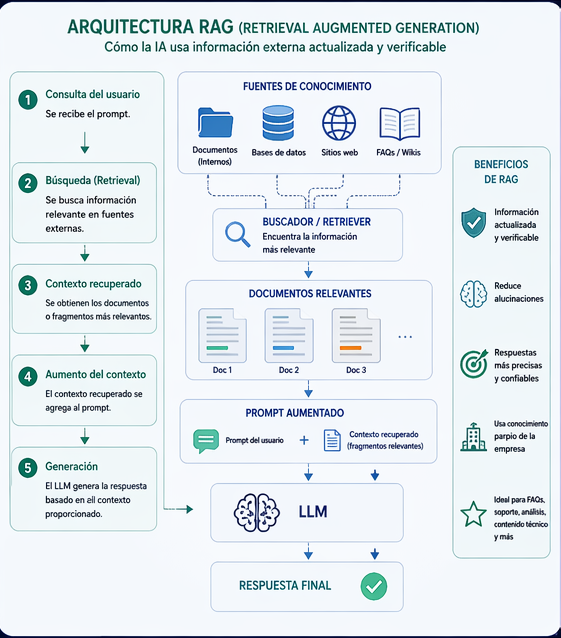
2. ¿Por qué esto es vital para las IAs?
El RAG resuelve los dos problemas más grandes de los modelos como ChatGPT o Gemini:
Elimina las alucinaciones: Al obligar a la IA a leer tus documentos, reduces drásticamente la posibilidad de que invente datos. Si la información no está en el documento, la IA dirá «no lo sé» en lugar de mentir.
Información al día: No necesitas reentrenar a la IA (proceso caro y lento) cada vez que cambian tus precios o servicios. Solo necesitas actualizar el archivo que el RAG consulta.
Ejemplo Práctico
Imagina que tienes un chatbot en tu canal de YouTube. Si un usuario pregunta por un video que publicaste ayer, una IA normal no lo sabrá porque su entrenamiento terminó hace meses. Con RAG, la IA busca en tu lista de videos recientes, encuentra el título y le responde al usuario con precisión quirúrgica.
Transformer: El «Cerebro» que revolucionó la IA
Presentado por Google en 2017 bajo el famoso título «Attention Is All You Need», el Transformer es la arquitectura de red neuronal que cambió las reglas del juego. Como lo mencionamos al inicio de este artículo, antes las IAs leían los textos palabra por palabra, de izquierda a derecha (como un humano). El Transformer lo cambió todo al permitir que la IA «mire» toda la oración al mismo tiempo.
El Secreto: El Mecanismo de atención (Attention)
Imagina que estás leyendo la frase: «El banco estaba cerrado porque había sido asaltado».
Para entender qué significa «banco» (¿un asiento o una entidad financiera?), tu cerebro mira la palabra «asaltado».
El Transformer hace exactamente eso mediante el Mecanismo de Atención: calcula matemáticamente qué palabras de una oración se relacionan más entre sí, sin importar qué tan lejos estén. Esto le permite captar el contexto profundo de una manera que las tecnologías anteriores no podían.
Procesamiento en paralelo (Velocidad)
A diferencia de sus predecesores (como las redes RNN), el Transformer no necesita esperar a terminar la palabra uno para empezar la dos. Puede procesar bloques gigantescos de datos en paralelo.
Resultado: Esto permitió entrenar modelos con miles de millones de datos (como los LLM) en tiempos récord, aprovechando toda la potencia de las tarjetas gráficas (GPUs).
De la «T» de GPT a la creación visual
Aunque nació para el texto (la «T» de GPT significa precisamente Transformer), esta arquitectura ha demostrado ser tan flexible que ahora se usa para:
Imágenes: Los Vision Transformers analizan fotos dividiéndolas en parches.
En otros campos por ejemplo permite ayuda a la ciencia a entender estructuras biológicas complejas de las proteínas y así en diversos campos.
Dato no menor: Transformer es como un lector superdotado. Mientras otros leen con el dedo siguiendo la línea, el Transformer toma una foto a la página completa y entiende instantáneamente cómo cada palabra afecta el significado de las demás. Es la base de la «magia» que ves en tu canal de YouTube cuando la IA resume un video complejo en segundos.
Multimodalidad: La IA que ya no solo lee, sino que «ve» y «escucha»
Hasta hace muy poco, las IAs estaban encerradas en silos: una servía para texto (LLM) y otra distinta para imágenes (Difusión). La Multimodalidad es la capacidad de un solo modelo de IA para procesar, comprender y generar múltiples tipos de datos (texto, imágenes, audio y video) de manera simultánea y fluida.
El espacio latente unificado
El secreto de la multimodalidad no es simplemente «pegar» un generador de imágenes a un chat. Técnicamente, ocurre porque el modelo ha sido entrenado para que las palabras y las imágenes compartan un mismo Espacio Latente.
Ejemplo: Para una IA multimodal, el concepto matemático de «manzana roja» es el mismo, ya sea que lo lea en un texto, lo vea en una foto o lo escuche en un audio. Esta conexión profunda permite que el modelo «entienda» la realidad en lugar de solo procesar archivos.
Casos de uso en el mundo real
La multimodalidad transforma la productividad porque elimina los pasos intermedios:
Visión a texto: Puedes subir la foto de un error de software en tu PC y la IA te explicará cómo arreglarlo paso a paso.
Voz a acción: Puedes hablarle a la IA con entonaciones naturales y ella detectará si estás bromeando, preocupado o si necesitas una respuesta urgente.
Video a análisis: Los modelos más avanzados pueden «ver» un video de 1 hora y decirte exactamente en qué minuto ocurre un evento específico.
El futuro: Agentes autónomos
La multimodalidad es el requisito indispensable para los Agentes de IA. Si quieres que una IA navegue por una página web para comprar un pasaje por ti, necesita «ver» los botones y «leer» las condiciones al mismo tiempo. Es el paso final para que la IA deje de ser una caja de texto y se convierta en un asistente que interactúa con el mundo físico y digital.
El futuro inmediato: La multimodalidad es tu superpoder. Imagina grabar un tutorial, subirlo a la IA y que ella automáticamente extraiga el guion, cree la descripción para YouTube y diseñe la miniatura basándose en lo que «vio» en el video. Ya no estamos en la era de «escribir prompts», estamos en la era de «dirigir experiencias».
Inferencia: El «momento de la verdad» de la IA
Si el entrenamiento es la etapa donde la Inteligencia Artificial asiste a la escuela para aprender de trillones de datos, la Inferencia es el examen final que rinde cada vez que tú le haces una pregunta. Es el proceso en el que un modelo ya entrenado aplica lo que sabe para deducir una respuesta ante una entrada de datos totalmente nueva.
Entrenamiento vs. Inferencia
Es fundamental no confundir estos dos procesos, ya que consumen recursos de forma muy distinta:
Entrenamiento: Es lento, carísimo y ocurre una sola vez (o pocas veces). Requiere miles de potentes tarjetas gráficas (GPUs) trabajando durante meses para «ajustar» el cerebro de la IA.
Inferencia: Es rápida y ocurre en milisegundos. Es lo que sucede cuando escribes un prompt y ves cómo la IA empieza a generar palabras. Aquí, la IA no está «aprendiendo» nada nuevo; simplemente está consultando su mapa interno para predecir el siguiente resultado lógico.
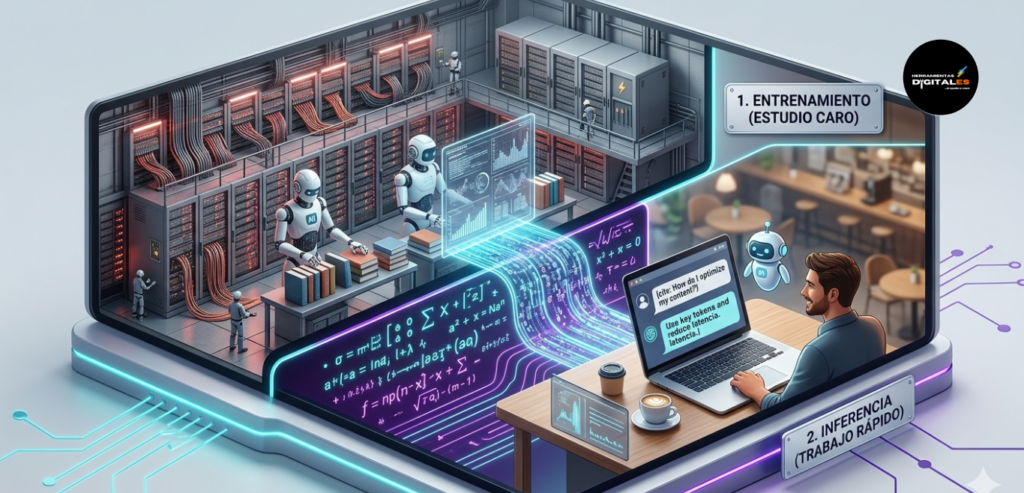
Métricas clave de la Inferencia
Latencia: Es el tiempo de espera desde que lanzas el prompt hasta que la IA empieza a responder. En herramientas digitales, buscamos la «baja latencia» para que la interacción sea instantánea.
Eficiencia: Se refiere a qué tan bien el modelo utiliza los recursos (memoria y procesador) para dar una respuesta. Un modelo eficiente te permite ahorrar costos y procesar más información en menos tiempo.
El costo de la inferencia
Cada vez que generas una imagen en tu canal de YouTube o generas un artículo, estás realizando una operación de inferencia.
Inferencia en la nube: Ocurre en los servidores de empresas como Google o OpenAI. Es potente, pero dependes de su conexión y velocidad.
Inferencia local: Gracias a técnicas como la Cuantización, hoy podemos hacer inferencia en nuestra propia laptop o celular. Es más privada y no consume internet, pero depende de la potencia de tu propio hardware.
Optimización para la velocidad
En el mundo profesional, buscamos que la inferencia sea lo más barata y rápida posible. Por eso existen modelos «pequeños» (como Gemini Flash) diseñados específicamente para tener una inferencia casi instantánea, ideal para chatbots de atención al cliente que deben responder sin demora.
Pesos y Parámetros: La anatomía de la inteligencia digital
Cuando escuchamos que un modelo como GPT-4 tiene «billones de parámetros», estamos hablando de su capacidad de almacenamiento y razonamiento. Pero, ¿qué son exactamente estos números y por qué determinan la calidad de la respuesta que recibes en tu pantalla?
¿Qué son los Parámetros?
En términos sencillos, los parámetros son las variables internas del modelo que se ajustan durante el proceso de entrenamiento. Imagina un tablero de control con miles de millones de «perillas» o interruptores. Cada vez que la IA estudia un dato nuevo, mueve esas perillas para entender mejor la relación entre las ideas.
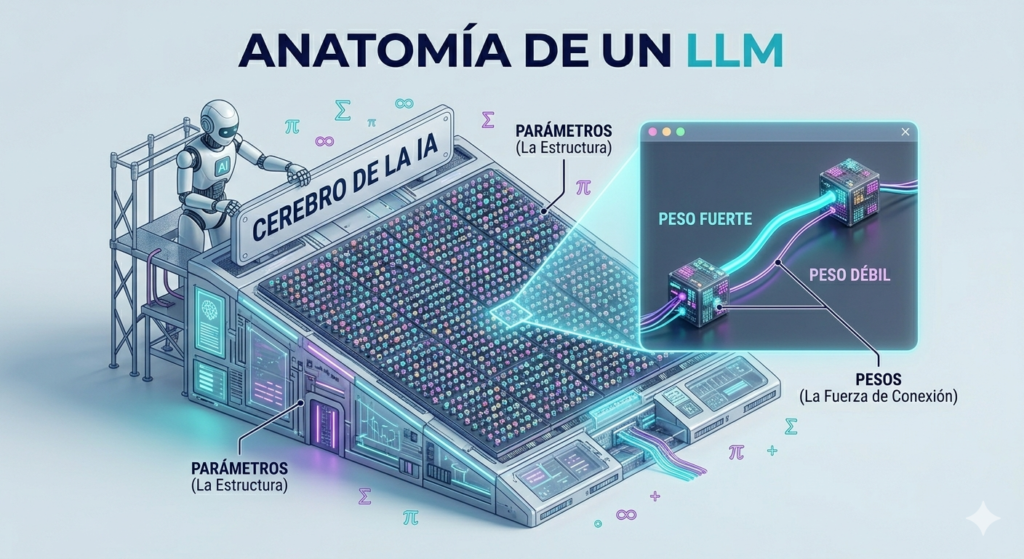
A mayor número de parámetros, el modelo suele ser capaz de entender matices más sutiles, idiomas complejos y conceptos abstractos.
¿Qué son los Pesos (Weights)?
Los pesos son un tipo específico de parámetro que determina la fuerza de la conexión entre dos piezas de información.
Si la IA lee la palabra «Lima», el peso de la conexión con la palabra «Perú» es altísimo.
Si lee «Lima», el peso de la conexión con la palabra «fruta» es moderado.
El peso de la conexión con la palabra «astronauta» es casi cero.
Durante el entrenamiento, la IA calibra estos pesos para que, al final, pueda predecir con exactitud qué palabra o píxel debe seguir al anterior.
¿Más parámetros significan siempre mejor IA?
No necesariamente. Existe una tendencia moderna hacia los modelos pequeños y eficientes. Un modelo con menos parámetros, pero entrenado con datos de «alta calidad», puede superar a un modelo gigante entrenado con datos «basura». Esto es vital para dispositivos móviles, donde no hay espacio para billones de parámetros.
Conclusión: Habla el lenguaje del mañana
Como habrás notado, el lenguaje de la IA generativa es vasto. En esta nueva era, donde la IA ha pasado de ser una curiosidad a ser nuestra herramienta de trabajo principal, conocer y dominar estos conceptos no es una cuestión de ego intelectual: es una ventaja competitiva directa.
Al entender términos como tokens, RAG o inpainting, dejas de ser un simple espectador para convertirte en el arquitecto de tu propia productividad. En «Herramientas Digitales» tenemos una filosofía clara: la tecnología solo es verdaderamente útil cuando se entiende.
Lo que viene a continuación
Este es solo el comienzo. En nuestra próxima entrega, seguiremos ampliando este glosario con un enfoque didáctico, eliminando tecnicismos innecesarios para que puedas aplicar cada concepto de inmediato en tus proyectos. Aquí también encontrarás otro glosario sobre IA
¡Tu momento ha llegado!
¿Cuál de estos términos te resultó más revelador? ¿Hay algún concepto que todavía te genere dudas?
Déjanos un comentario abajo e interactúa con nuestra comunidad. ¡Tu feedback es el prompt que nos ayuda a generar mejor contenido!
¿Te resultó útil?, aquí más glosarios:

IA Operativa 2026: Guía Definitiva de Automatización Avanzada

Dominando la IA Generativa Avanzada: Glosario Técnico – Parte 2