¿Qué encontraremos en este artículo?
La IA Operativa es el ecosistema de arquitecturas y herramientas que permiten integrar modelos de inteligencia artificial (IA) en flujos de trabajo autónomos y procesos de ejecución en tiempo real. Mientras que la IA generativa tradicional se enfoca en la creación de contenido, la IA Operativa se especializa en la acción: es el puente técnico que convierte las predicciones en resultados tangibles dentro de una infraestructura empresarial.
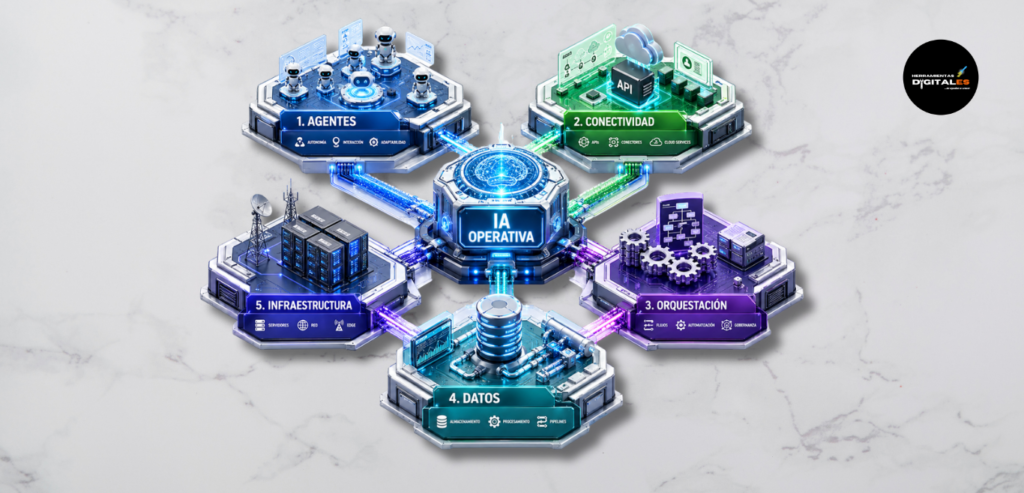
En la actualidad, no basta con tener un modelo de lenguaje potente; el verdadero reto radica en la orquestación modular de estos sistemas. Para los profesionales que buscan escalar su eficiencia, comprender conceptos como el Edge Computing o la Arquitectura Orientada a Eventos no es opcional, es una necesidad estratégica para evitar silos tecnológicos o datos aislados.
I. Agentes y Ejecución Autónoma
La cúspide de la IA Operativa no se encuentra en la simple respuesta a un prompt, sino en la capacidad de delegar la ejecución a sistemas con capacidad de juicio. Esta sección aborda los componentes que permiten que la inteligencia pase de ser un consultor pasivo a un actor activo dentro de un ecosistema digital. Hablamos de la transición de sistemas basados en reglas rígidas hacia entidades capaces de gestionar la incertidumbre y completar objetivos complejos mediante la iteración y el razonamiento.
Agentes Autónomos
Definición Técnica: Un Agente Autónomo es una entidad de software impulsada por Modelos de Lenguaje de Gran Escala (LLM) o Modelos Multimodales (LMM), diseñada para perseguir un objetivo específico de manera independiente. A diferencia de un chatbot, un agente posee un bucle de razonamiento (Reasoning Loop) que le permite planificar tareas, utilizar herramientas externas (herramientas de búsqueda, navegadores, código) y corregir su propio curso de acción sin intervención humana constante.
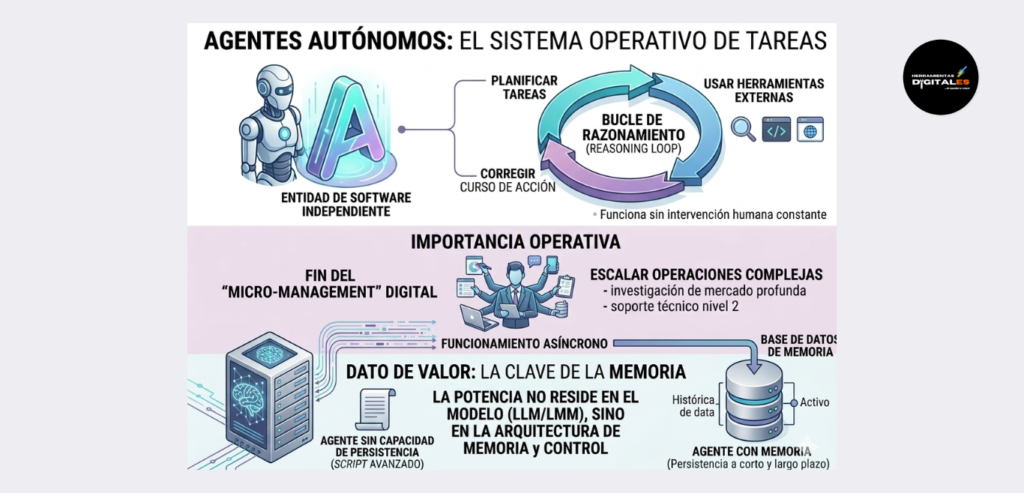
Importancia: Para el profesional moderno, los agentes representan el fin del «micro-management» digital. Son vitales porque permiten escalar operaciones complejas (como la investigación de mercado profunda o el soporte técnico nivel 2) de forma asíncrona, funcionando como empleados digitales que no solo procesan información, sino que ejecutan decisiones basadas en el contexto.
Dato de valor: La verdadera potencia de un agente no reside en el modelo que lo impulsa, sino en su arquitectura de memoria y control. Un agente sin capacidad de persistencia de estado (memoria a corto y largo plazo) es simplemente un script avanzado; un agente con memoria es un sistema operativo de tareas.
Ejemplo Práctico: Imagina que necesitas realizar una auditoría de precios de la competencia. Un bot tradicional extraería datos de una lista de URLs predefinida. Un Agente Autónomo recibe la instrucción: «Encuentra quién tiene el mejor precio para el producto X, verifica si tienen stock y redacta un reporte comparativo». El agente buscará las webs, navegará por ellas, manejará errores si una página no carga y entregará el informe final por correo.
RPA (Robotic Process Automation)
Definición Técnica: El RPA o Automatización Robótica de Procesos es una tecnología que utiliza «bots» de software para emular las acciones humanas en interfaces digitales. A diferencia de los agentes que mencionamos antes, el RPA tradicional se basa en reglas lógicas estrictas y estructuradas (si pasa A, haz B). Es la herramienta ideal para manejar tareas repetitivas en sistemas que no tienen una API moderna, como rellenar formularios, mover archivos o extraer datos de facturas. Según la documentación técnica de UiPath, líder en el sector, el RPA actúa como una fuerza de trabajo digital que elimina el error humano en procesos mecánicos.
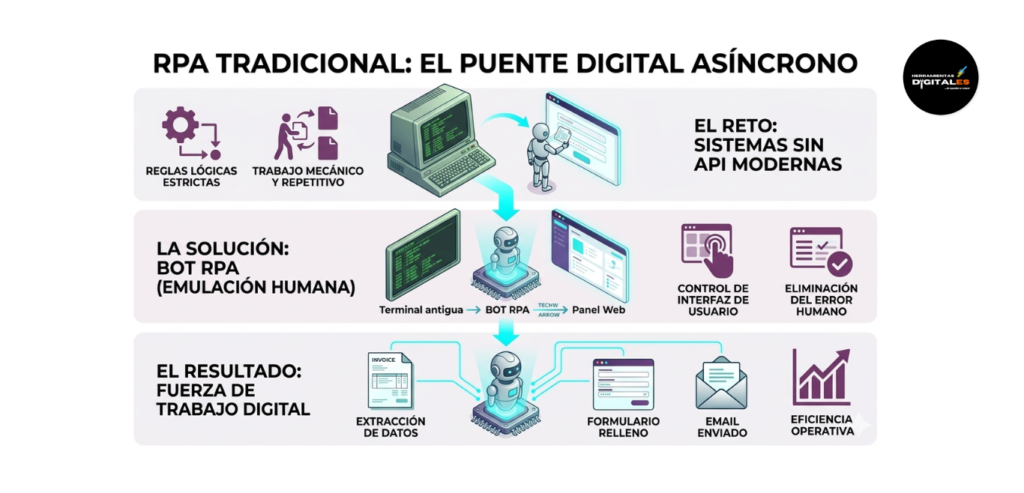
Importancia: Para un creador o dueño de negocio, el RPA es vital porque permite «conectar» software antiguo con herramientas modernas sin necesidad de cambiar todo el sistema. Es el músculo que ejecuta las tareas aburridas de forma incansable, permitiendo que la IA Operativa se encargue de la parte estratégica mientras el bot se encarga del clic a clic.
Dato de valor: No confundas RPA con IA. El RPA es hacer (ejecución), mientras que la IA es pensar (decisión). La magia ocurre en la «Automatización Inteligente», donde la IA le dice al bot de RPA qué debe procesar tras analizar un contexto complejo.
Ejemplo práctico: Imagina que cada mañana recibes 50 correos con archivos PDF de pedidos. Un bot de RPA puede configurarse para abrir cada correo, descargar el archivo, entrar en tu software de contabilidad antiguo y transcribir los datos campo por campo, finalizando con un clic en «Guardar». Lo hace en segundos y sin equivocarse en un solo número.
Excelente, cerramos el primer pilar de Ejecución Autónoma con una de las tendencias más disruptivas para la agilidad empresarial. El enfoque aquí es la democratización de la tecnología: cómo la IA permite que cualquier profesional construya soluciones sin ser un experto en sintaxis de programación.
Automatización Low-Code
Definición Técnica: La automatización Low-Code (bajo código) es un enfoque de desarrollo de software que permite crear aplicaciones y flujos de trabajo mediante interfaces gráficas visuales en lugar de programación manual tradicional. En el contexto de la IA Operativa, estas plataformas utilizan conectores preconfigurados y lógica de «arrastrar y soltar» (drag-and-drop), permitiendo que la lógica de negocio se implemente rápidamente. Según la visión técnica de Microsoft Power Automate, el Low-Code reduce la barrera de entrada para la innovación, permitiendo que el desarrollo sea hasta 10 veces más rápido que el método convencional.
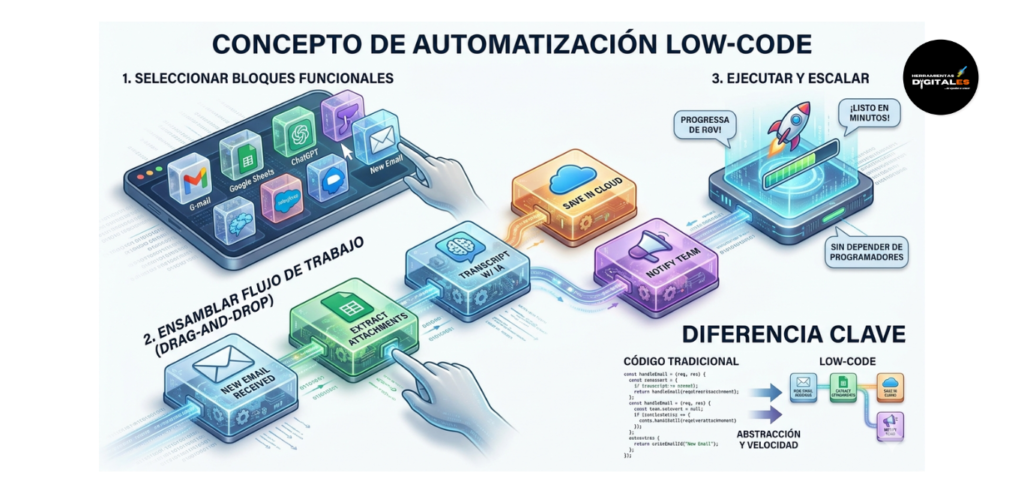
Importancia: Para un creador de contenido o dueño de negocio, el Low-Code es el «gran ecualizador». Es vital porque permite prototipar e implementar soluciones complejas —como un sistema de atención al cliente automatizado— en cuestión de horas. Elimina la dependencia total de departamentos de IT sobrecargados, otorgando al profesional el poder de ser el arquitecto de sus propias herramientas.
Dato de valor: El Low-Code no sustituye al código; lo encapsula. La verdadera maestría consiste en saber cuándo usar una herramienta visual para la rapidez y cuándo insertar un bloque de código personalizado (No-Code vs. Low-Code) para resolver una necesidad técnica específica que la interfaz estándar no cubre.
Ejemplo práctico: Imagina que quieres automatizar una web o algún emprendimiento digital. Puedes usar una plataforma Low-Code para crear un flujo donde: cada vez que publiques un video en YouTube, la IA extraiga la transcripción, genere un resumen para WordPress, cree una imagen destacada y programe un post en LinkedIn. Todo esto se configura visualmente uniendo «bloques» de cada servicio, sin escribir una sola línea de Python.
II. Conectividad y Arquitectura de Sistemas
En el ámbito de la IA Operativa, la conectividad no es simplemente tener internet; es la capacidad de que aplicaciones distintas hablen el mismo idioma y compartan datos de forma instantánea. Por otro lado, la arquitectura es el plano maestro que define cómo se organizan esos componentes para que el sistema sea escalable, seguro y eficiente.
Sin una conectividad robusta, la inteligencia artificial no puede acceder a los datos que necesita para aprender o ejecutar acciones. Una buena arquitectura garantiza que, si un componente falla o necesita actualizarse, el resto del ecosistema siga funcionando sin interrupciones.
API REST
Definición Técnica: Una API REST (Representational State Transfer) es un conjunto de reglas y protocolos que permiten que dos sistemas de software se comuniquen a través de la web utilizando el protocolo HTTP. Es el estándar de oro de la web moderna. Funciona mediante «peticiones» y «respuestas»: un sistema solicita información (o envía una orden) y el otro responde con los datos necesarios, generalmente en un formato ligero y fácil de leer llamado JSON. Según la documentación técnica de IBM sobre APIs, la arquitectura REST es valorada por su ligereza y su capacidad de separar el cliente del servidor.
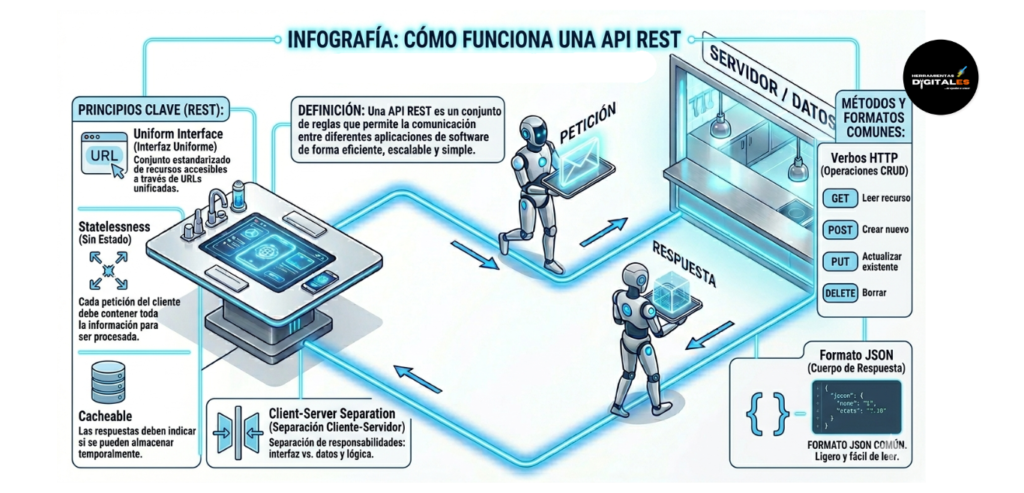
Importancia: Para un estratega digital, las APIs son las «puertas de entrada» a cualquier servicio. Son vitales porque permiten que tu página web o tu herramienta de IA se conecte con Google Drive, Stripe, OpenAI o X. Sin APIs REST, cada software sería una isla; gracias a ellas, podemos construir sistemas complejos uniendo las mejores funciones de diferentes proveedores.
Dato de valor: Piensa en la API REST como el «contrato de comunicación» de tu sistema. No necesitas saber cómo funciona el software del otro lado por dentro; solo necesitas saber qué pedir y qué formato de respuesta esperar. Esto permite una transparencia operativa total.
Ejemplo práctico: Cuando utilizas un plugin en una web para mostrar tus últimos mensajes en X, el plugin no entra a tu cuenta de X, como un humano. En su lugar, hace una petición a la API REST de X diciendo: «Dame los últimos 5 mensajes de este usuario». X verifica la identidad y le entrega los datos en una fracción de segundo para que se muestren en tu web.
Webhooks
Definición Técnica: Un Webhook (también conocido como una «API inversa» o callback HTTP) es un mecanismo que permite a una aplicación enviar información en tiempo real a otra aplicación automáticamente cuando ocurre un evento específico. A diferencia de las API REST, donde la aplicación A debe preguntar constantemente a la aplicación B si hay novedades (técnica conocida como polling), en un Webhook es la aplicación B la que «llama» a la aplicación A en el momento justo en que sucede algo. Como señala la documentación técnica de Stripe, líder en pagos online, los Webhooks son fundamentales para reaccionar a eventos de forma asíncrona y eficiente.
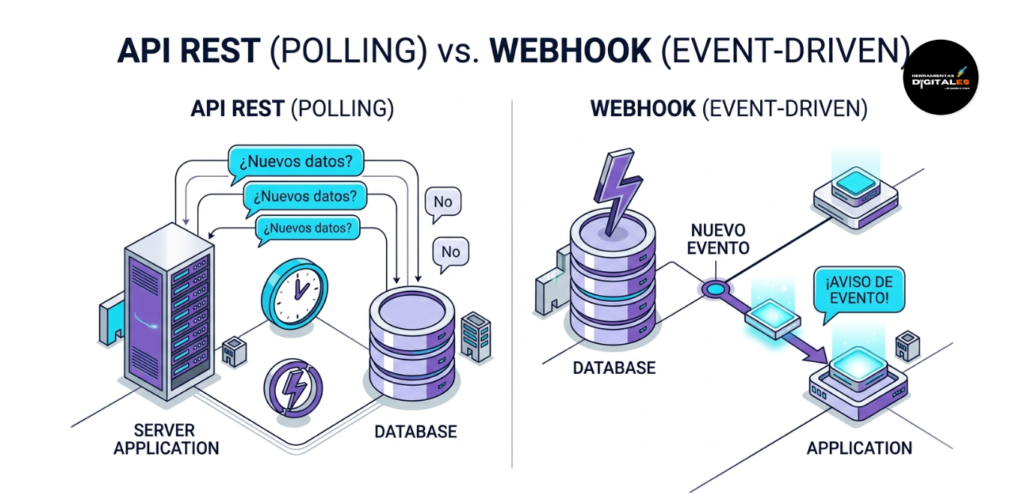
Importancia: Para un comerciante, los Webhooks son los «sensores de movimiento» de su negocio. Son vitales porque eliminan el desperdicio de recursos computacionales. No necesitas gastar energía preguntando cada minuto «¿Ya me pagaron?»; simplemente configuras un Webhook para que tu pasarela de pagos te avise instantáneamente cuando el dinero entre. Es el pilar de la automatización Event-Driven (basada en eventos).
Dato de valor: Las APIs son para pedir; los Webhooks son para escuchar. La API requiere que tú inicies la acción; el Webhook requiere que tú prepares tu sistema para recibir una acción externa inesperada (un endpoint de recepción).
Ejemplo práctico: Imagina que vendes un curso online en una web. Si usaras solo APIs, tu servidor tendría que preguntar a PayPal cada minuto si el usuario «X» pagó. Con un Webhook, tú simplemente le dices a PayPal una vez: «Cuando alguien pague, envíame los datos a esta dirección a mi web». PayPal lo hace, y tu web le da acceso al curso al usuario al instante, sin latencia.
Middleware
Definición técnica: El Middleware es una capa de software que se sitúa entre el sistema operativo y las aplicaciones que se ejecutan en él, o entre dos aplicaciones distintas. Su función principal es actuar como un «traductor» y «organizador» universal. En un ecosistema de IA Operativa, el middleware gestiona la complejidad de la red, permitiendo que sistemas heterogéneos (que no fueron diseñados para trabajar juntos) intercambien datos de forma coherente. Según la documentación técnica de Red Hat sobre Middleware, es el «tejido conectivo» que sostiene las aplicaciones modernas.
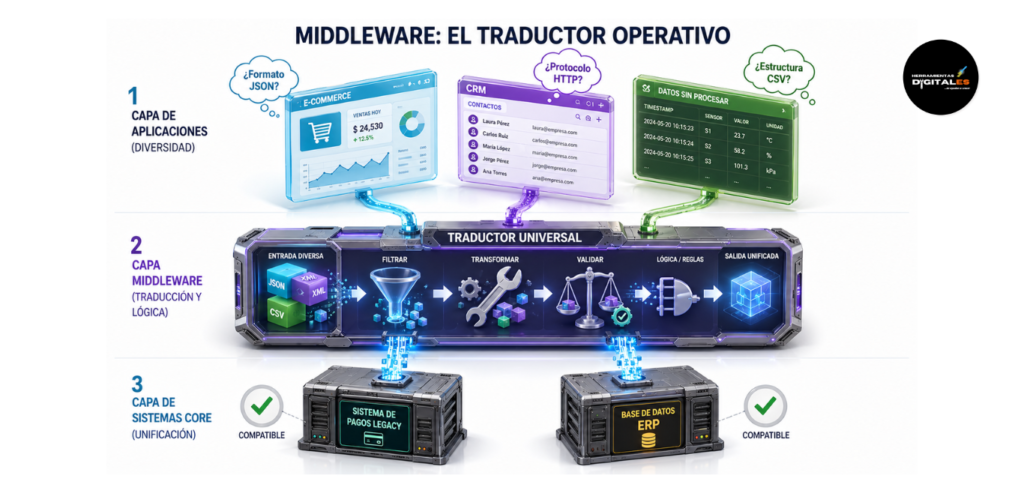
Importancia: Para un desarrollador o arquitecto de contenido, el middleware es vital porque resuelve el problema de la fragmentación. Es el componente que permite que un dato recolectado por un Agente Autónomo sea transformado, validado y enviado a una base de datos antigua sin que el sistema colapse. Sin el middleware, tendrías que escribir código personalizado para cada pequeña conexión; con él, centralizas la lógica de comunicación.
Dato de valor: El Middleware es el «pegamento inteligente». No solo transporta datos; puede filtrarlos, enriquecerlos y asegurar que solo la información relevante pase de un punto a otro, garantizando la transparencia operativa y reduciendo la carga en los servidores finales.
Ejemplo práctico: Imagina que tienes una tienda online. Cuando un cliente compra, el Middleware recibe la señal de la web, pero antes de pasarla al sistema de envíos, verifica si hay stock en el almacén, convierte el precio de dólares a euros y registra la transacción en tu software de contabilidad. Todo ocurre en esa «capa intermedia» de forma invisible para el usuario.
Con el Middleware como base conceptual, pasamos a la evolución moderna de esta tecnología. Si el Middleware es el «pegamento», el iPaaS es la fábrica completa de pegamento en la nube, lista para usarse sin instalar servidores.
Integraciones iPaaS
Definición técnica: El iPaaS (Integration Platform as a Service) es una suite de servicios en la nube que permite a los usuarios conectar aplicaciones, datos y procesos de forma centralizada. A diferencia del middleware tradicional, que suele requerir una infraestructura propia, el iPaaS vive totalmente en el cloud. Según la arquitectura definida por Gartner, estas plataformas permiten gestionar flujos de integración complejos (entre aplicaciones SaaS y sistemas locales) desde un único panel de control.
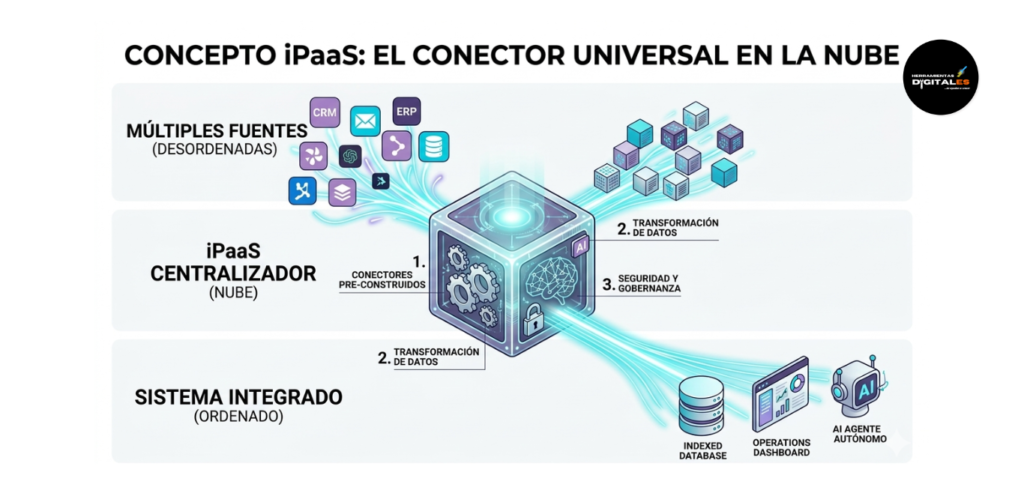
Importancia: Para un creador digital o empresa en crecimiento, el iPaaS es vital porque elimina la complejidad de mantener servidores de integración. Es la herramienta que permite que tu ecosistema de IA Operativa sea ágil; si mañana cambias de CRM o de plataforma de email, el iPaaS te permite reconfigurar la conexión en minutos mediante conectores pre-construidos, manteniendo la integridad de tus datos.
Dato de valor: La gran ventaja del iPaaS no es solo conectar «A con B», sino su capacidad de Gobernanza de Datos. Te permite ver, en un solo lugar, qué datos están viajando por toda tu empresa, detectar fallos en tiempo real y asegurar que la seguridad se aplique de forma uniforme a todas las conexiones.
Ejemplo práctico: Plataformas como Make (antiguo Integromat) o Zapier son ejemplos perfectos de iPaaS. Imagina un flujo donde un cliente llena un formulario en tu web: el iPaaS recibe el dato, lo pasa por una IA para analizar el sentimiento del mensaje, crea una tarea en Trello, guarda el contacto en tu base de datos y envía una alerta a Slack. Todo ocurre en la nube del proveedor de iPaaS.
III. Orquestación y flujos inteligentes
Una vez que los sistemas están conectados (Pilar II) y los agentes están listos para actuar (Pilar I), es necesario una «mente maestra» que dirija el tráfico. La IA Operativa alcanza su máximo potencial en esta capa, donde la automatización deja de ser una lista lineal de pasos para convertirse en un ecosistema capaz de tomar decisiones, ramificar procesos y gestionar prioridades de forma autónoma. Aquí es donde diseñamos la lógica que permite que las herramientas no solo trabajen, sino que colaboren entre sí de forma coherente.
Orquestación de modelos
Definición técnica: La Orquestación de Modelos es la gestión coordinada de múltiples modelos de inteligencia artificial (como LLMs, modelos de visión o de voz) para completar una tarea compleja que un solo modelo no podría resolver con eficiencia. No se trata de usar una sola IA para todo, sino de crear una secuencia lógica donde cada modelo interviene según su especialidad. Según la documentación técnica de LangChain, la orquestación permite el «encadenamiento» (chaining) de pensamientos y acciones, optimizando tanto la precisión como el consumo de recursos (tokens).
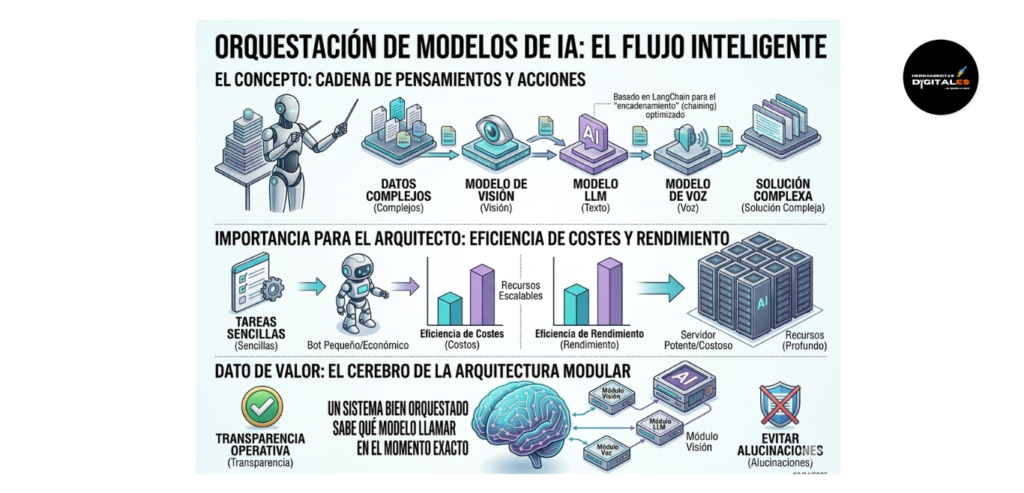
Importancia: Para un arquitecto de soluciones, la orquestación es vital porque introduce la eficiencia de costes y rendimiento. Permite utilizar modelos pequeños y rápidos (y económicos) para tareas sencillas, reservando los modelos más potentes y costosos solo para los pasos que requieren un razonamiento profundo. Esto garantiza que el sistema sea escalable y financieramente viable a largo plazo.
Dato de valor: La orquestación es el «cerebro» de la arquitectura modular. Un sistema bien orquestado no es el que usa la IA más grande, sino el que sabe qué modelo llamar en el momento exacto para garantizar la transparencia operativa y evitar alucinaciones en los datos.
Ejemplo práctico: Imagina un sistema automatizado de gestión de contenidos para una web:
Un modelo ligero escanea los comentarios de los usuarios para detectar spam.
Si el comentario es una duda técnica, se envía a un modelo especializado en código.
Si el comentario es una sugerencia de tema, se orquesta hacia un modelo creativo que genera un esquema de artículo.
Finalmente, un modelo de control de calidad revisa todo antes de guardarlo en tu base de datos.
Damos un paso fundamental en la complejidad técnica. Si la orquestación (Punto 8) es el director de orquesta que sigue una partitura, la Arquitectura Dirigida por Eventos (EDA) es un equipo de jazz: cada músico reacciona instantáneamente a lo que tocan los demás, sin esperar una orden central. Es el cambio de «esperar instrucciones» a «reaccionar en tiempo real».
Event-Driven Architecture
Definición técnica: La Arquitectura Dirigida por Eventos (Event-Driven Architecture o EDA) es un paradigma de diseño de software en el que el flujo del sistema está determinado por la detección de «eventos». Un evento es cualquier cambio de estado significativo o acción detectada en el ecosistema (ej: «nuevo pedido», «error de sensor», «pago completado»).
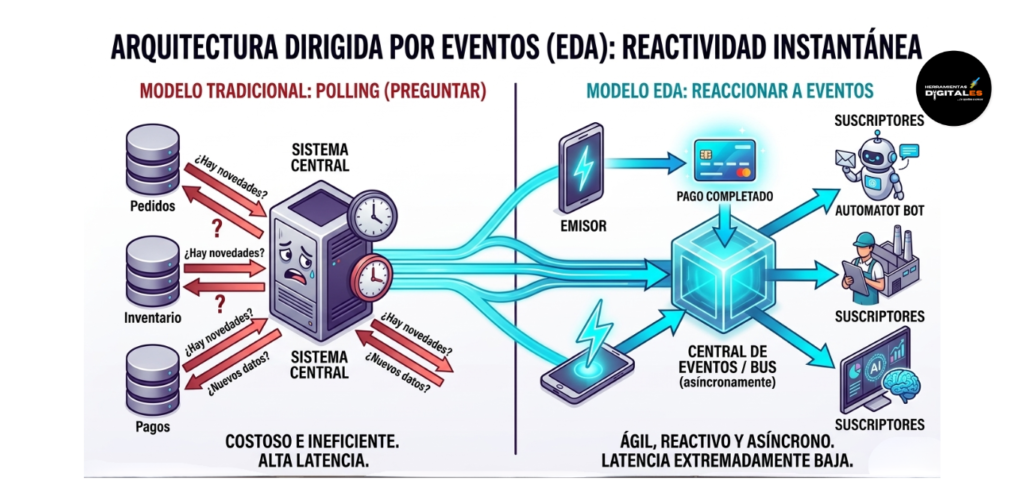
En lugar de que un sistema central pregunte constantemente «¿hay novedades?» (Polling), los sistemas basados en EDA tienen emisores que «publican» el evento y suscriptores que «reaccionan» a él instantáneamente y de forma asíncrona. Según la visión técnica de AWS sobre Arquitecturas de Eventos, EDA permite crear sistemas altamente desacoplados, escalables y con una latencia extremadamente baja.
Importancia: Para un estratega digital que busca la máxima agilidad, EDA es vital porque habilita la IA Operativa de Tiempo Real. Permite que tus agentes autónomos o flujos de trabajo inteligentes no pierdan tiempo esperando respuestas. Si ocurre un evento crítico, la IA reacciona en milisegundos, permitiendo una hiper-personalización del cliente o la mitigación inmediata de un error técnico antes de que impacte en los resultados al usuario.
Dato de valor: ElPolling (preguntar) es costoso e ineficiente; EDA (reaccionar) es ágil y reactivo. La verdadera transparencia operativa se logra cuando no necesitas buscar la información, sino que la información te encuentra a ti en el momento exacto en que ocurre.
Ejemplo práctico: Imagina una plataforma de trading. Cuando el precio de una acción cruza un límite (el Evento), el sistema no espera a que un humano lo note. Instantáneamente:
Un agente de IA analiza si es una oportunidad de compra.
Otro sistema actualiza el panel del usuario.
Un tercer sistema envía una alerta por Slack.
Todo ocurre en paralelo y de forma asíncrona, reaccionando a un solo cambio de estado.
IV. Gestión de Datos en Movimiento
En un ecosistema de automatización avanzada, los datos rara vez permanecen estáticos. Fluyen constantemente entre una web, tu CRM, tus bases de datos y tus agentes de IA. La Gestión de Datos en Movimiento se refiere al conjunto de tecnologías, protocolos y estrategias diseñadas para capturar, procesar, transformar y transportar esta información de forma instantánea y segura. No se trata solo de mover datos de «A a B»; se trata de asegurar que lleguen en el formato correcto, en el momento exacto y con la integridad garantizada, permitiendo que la IA tome decisiones basadas en la realidad actual, no en datos históricos obsoletos. Es la base que transforma la información cruda en inteligencia accionable.
Pipelines de datos
Definición Técnica: Un Pipeline de Datos (o tubería de datos) es una serie de procesos automatizados que mueven datos desde una o más fuentes de origen hacia un destino final (como una base de datos o un modelo de IA) para su análisis o acción.
En el contexto de la IA Operativa, estos pipelines suelen seguir el paradigma ETL (Extract, Transform, Load) o ELT. Automáticamente extraen los datos (ej: un nuevo lead en la web), los transforman (ej: limpian el formato del teléfono, enriquecen el perfil con IA) y los cargan en el sistema de destino (ej: el CRM). Según la arquitectura definida por Google Cloud sobre Data Pipelines, la automatización de estos flujos elimina el error humano y garantiza la consistencia de los datos en toda la organización.
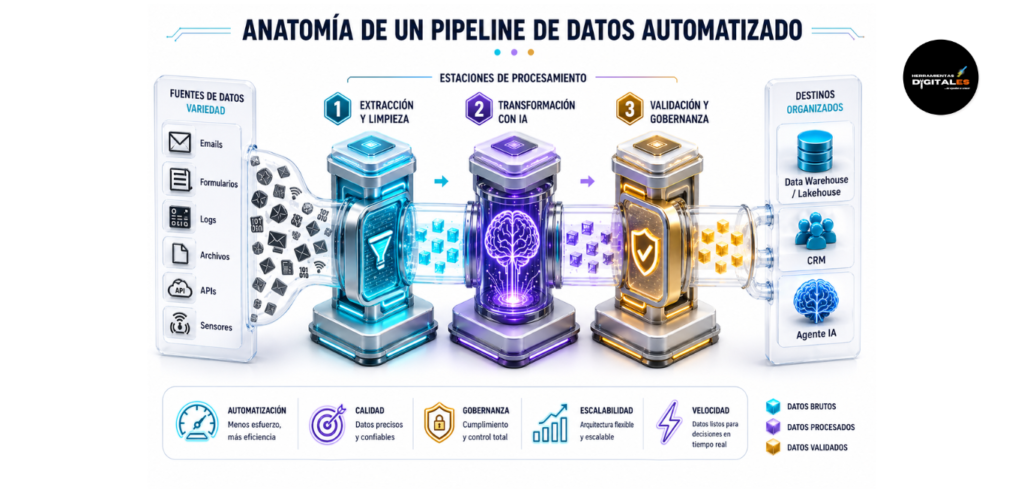
Importancia: Para un creador de contenido o dueño de negocio, los Pipelines de Datos son vitales porque garantizan la precisión técnica y la transparencia operativa. Son el «sistema circulatorio» que alimenta a tus agentes autónomos. Sin pipelines bien diseñados, tu IA estaría operando con datos sucios, incompletos o retrasados, lo que lleva a decisiones incorrectas y pérdida de confianza en la automatización.
Dato de valor: La automatización avanzada es tan buena como la calidad del dato que la alimenta. Un pipeline de datos profesional no solo mueve la información; incluye etapas de validación y limpieza que actúan como filtros, asegurando que solo el «agua pura» (datos limpios) llegue a tu IA y a tus clientes.
Ejemplo práctico: Pipeline de Gestión de Reseñas:
1. Fuente: Un cliente deja una reseña en Google My Business.
2. Extracción: El pipeline detecta la nueva reseña automáticamente.
3. Transformación (IA): Un Agente de IA analiza el sentimiento (positivo/negativo) y extrae las palabras clave.
4. Carga: Si la reseña es negativa, el pipeline crea una alerta urgente en Slack y registra el caso en el CRM para seguimiento.
Damos un paso más profundo en la ingeniería de datos. Si los Pipelines (Punto 12) son las tuberías, el ETL es la receta y el proceso químico que ocurre dentro de esas tuberías para purificar y transformar el agua. Es el estándar clásico para garantizar la calidad del dato antes de que la IA lo toque.
ETL (Extract, Transform, Load)
Definición técnica: ETL es el acrónimo de Extract (Extraer), Transform (Transformar) y Load (Cargar). Es el proceso tradicional de integración de datos que sigue un orden estricto: primero, los datos se extraen de múltiples fuentes de origen desordenadas; segundo, se mueven a un área de «staging» o memoria temporal donde se transforman (se limpian, filtran, anonimizan o combinan usando reglas de negocio); y finalmente, los datos ya purificados se cargan en un almacén de destino (como un Data Warehouse o CRM).
Según la arquitectura de datos definida por Informatica, líder en gestión de datos, el ETL es fundamental para garantizar que el sistema de destino solo reciba datos de alta calidad y listos para el análisis.
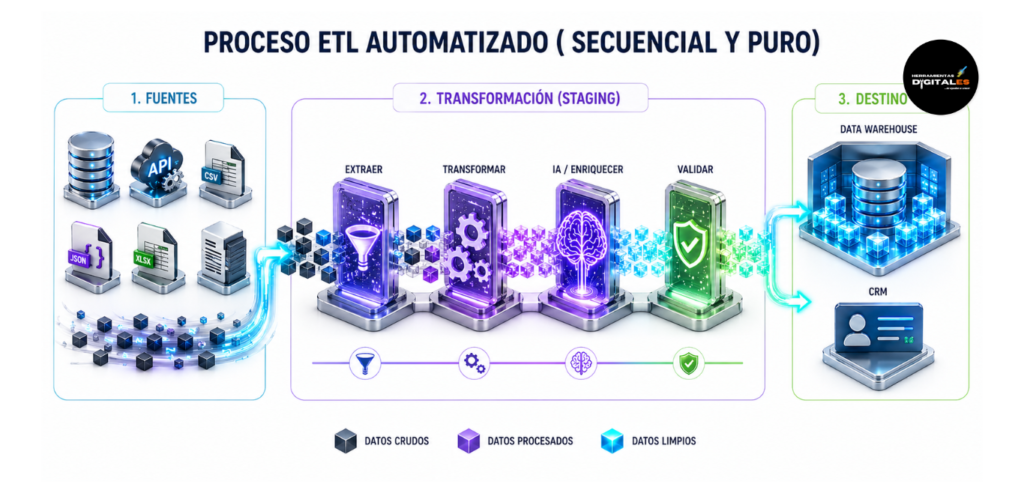
Importancia: Para un estratega digital que maneja información sensible o compleja, el ETL Automatizado es vital porque asegura la Gobernanza de Datos. Al realizar las transformaciones antes de cargar los datos, garantizas que ninguna información «sucia», incorrecta o sensible (Pll) llegue a tu CRM o a tus modelos de IA operativos. Es el filtro de seguridad y calidad definitivo que mantiene la integridad de tu ecosistema tecnológico.
Dato de valor: El ETL es el proceso de «cocinar» los datos. No sirves los ingredientes crudos y sucios (datos de origen); los lavas, cortas y cocinas (transformas) en la cocina (servidor de staging) y solo sirves el plato terminado (datos limpios) en el comedor (destino). Esto asegura que la precisión técnica de tu IA sea máxima.
Ejemplo práctico: Pipeline de Consolidación de Clientes:
1. Extraer: Automatizas la extracción de nuevos clientes desde Shopify, Stripe y tu formulario de contacto web.
2. Transformar (El motor ETL):
Limpia formatos de email duplicados.
Convierte todas las monedas a Euros.
Usa IA para verificar si el nombre está bien escrito.
Anonimiza los datos si no hay consentimiento GDPR.
3. Cargar: Carga este perfil de cliente único y perfecto en tu CRM centralizado.
Pasamos de gestionar los datos que ya tienes (ETL/Pipelines) a la capacidad de salir a buscar los datos que necesitas. En un ecosistema de IA Operativa, el scraping automatizado es el sentido de la vista: le permite a tus agentes ver qué hace la competencia o qué se dice en el mercado sin depender de una API.
Web Scraping Automatizado
Definición técnica: El Web Scraping Automatizado es la técnica de utilizar software (scripts, bots o agentes) para navegar por sitios web de forma automática, simulando el comportamiento humano, con el objetivo de extraer información específica y estructurarla. En lugar de copiar y pegar manualmente, un scraper extrae el código HTML de una página, localiza los datos deseados (precios, textos, imágenes) y los guarda en una base de datos o CSV. Según la documentación de proyectos de scraping avanzados, el scraping moderno implica gestionar complejidades como el renderizado de JavaScript (usando navegadores «headless»), la rotación de proxies para evitar bloqueos y la resolución de CAPTCHAs.

Importancia: Para un creador de contenido o dueño de negocio, el scraping automatizado es vital porque proporciona inteligencia competitiva y enriquecimiento de datos. Es la herramienta que te permite monitorizar los precios de tus rivales en tiempo real, recopilar reseñas de productos en plataformas de terceros para analizar el sentimiento con IA, o descubrir tendencias de búsqueda antes que nadie. Transforma la web pública en tu base de datos privada, alimentando a tu IA con información fresca y externa.
Dato de valor: El scraping automatizado no es solo extraer; es respetar y estructurar. Un scraping profesional opera con «cortesía operativa» (respetando
robots.txty no saturando servidores) y utiliza IA para limpiar los datos mientras los extrae, asegurando que la información llegue lista para la acción.
Ejemplo práctico: Monitorización de Precios de Competencia:
1. Activación: Un flujo orquestado activa un agente de scraping cada noche.
2. Ejecución: El agente navega por 10 webs de competidores, simulando un usuario real.
3. Extracción: Extrae el nombre del producto, el precio y si está en stock.
4. Acción: Si el precio de un competidor baja de cierto umbral, el sistema envía una alerta por Slack y ajusta automáticamente tu precio si tienes esa lógica activa.
V. Infraestructura crítica y velocidad
Llegamos a la capa que soporta todo el peso operativo de la automatización avanzada. En el ecosistema de IA Operativa, la infraestructura no es simplemente «un servidor donde alojar mi web»; es el conjunto de tecnologías de red, almacenamiento, computación y seguridad diseñadas para garantizar que los procesos críticos de tu negocio ocurran a una velocidad imperceptible para el ser humano y de forma ininterrumpida. La velocidad de ejecución y la baja latencia no son lujos; son requisitos técnicos para que una IA pueda reaccionar en tiempo real. Esta sección aborda los cimientos físicos y lógicos necesarios para que tu empresa sea realmente ágil, fiable y segura en la era digital.
Edge Computing
Definición técnica: El Edge Computing (o computación perimetral) es un paradigma de computación distribuida que consiste en procesar los datos lo más cerca posible de la fuente que los genera (el «borde» o edge de la red), en lugar de enviarlos a un centro de datos en la nube centralizado y lejano. Al acercar la potencia de computación al dispositivo (ej: un sensor, una cámara, el navegador del usuario), se reduce drásticamente la latencia y el ancho de banda necesario. Según la definición técnica de Accenture sobre Edge Computing, esta arquitectura permite una respuesta casi instantánea de la IA al eliminar el viaje de ida y vuelta de los datos a la nube central.
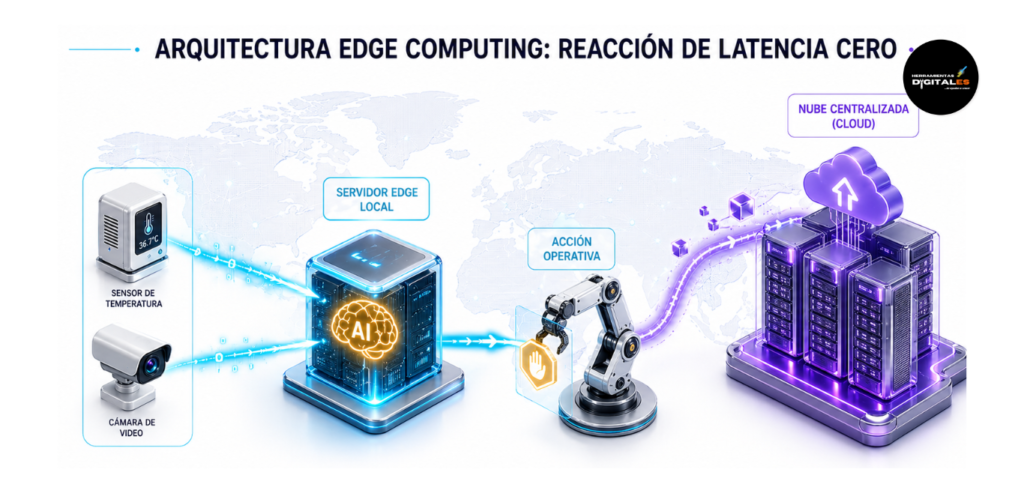
Importancia: Para un creador digital o empresa que requiere máxima reactividad, el Edge Computing es vital porque habilita la automatización de tiempo real crítico. Permite que un Agente de IA alojado en tu propia red tome decisiones críticas (como detener una línea de producción ante un error o ajustar un precio en milisegundos) sin esperar a que el servidor central responda. Es la tecnología que separa a los sistemas que «aprenden» de los sistemas que «actúan» instantáneamente en el mundo operativo.
Dato de valor: El Edge Computing es el sistema de reflejos de tu empresa. Mientras que la nube central es el cerebro que planifica y almacena a largo plazo, el Edge es la médula espinal que permite reaccionar a un estímulo doloroso (un error operativo) de forma inmediata, sin «pensarlo» en la nube central. Garantiza la máxima precisión técnica con latencia cero.
Ejemplo práctico: Visión por Computadora en Almacén:
Activación: Una cámara de seguridad detecta que un producto se ha caído.
Ejecución (Edge): En lugar de enviar el video a Google Cloud para analizarlo, la propia cámara (o un pequeño servidor en el almacén) tiene un modelo de IA ejecutándose.
Acción: En milisegundos, el Edge detecta la caída y detiene el robot que iba a pasar por allí, evitando un accidente.
Si el Edge Computing (Punto 17) es la ubicación física donde ocurre la magia, el Procesamiento en Tiempo Real es la capacidad lógica de digerir esos datos mientras se generan. Pasamos de procesar «lotes» de información estática a gestionar un flujo infinito de datos vivos.
Procesamiento en Tiempo Real
Definición técnica: El Procesamiento en Tiempo Real (Real-Time Processing) es una arquitectura de datos diseñada para capturar, procesar y entregar resultados en un intervalo de tiempo extremadamente corto, generalmente medido en milisegundos. A diferencia del procesamiento por lotes (Batch Processing), donde los datos se acumulan para procesarse horas después, el tiempo real utiliza tecnologías de Stream Processing (Procesamiento de Flujos) como Apache Kafka o Amazon Kinesis.
Estas herramientas permiten que la IA analice cada bit de información en el instante en que «nace». Según la arquitectura de Microsoft sobre Real-Time Analytics, el sistema debe estar diseñado para manejar una latencia mínima y una disponibilidad máxima.
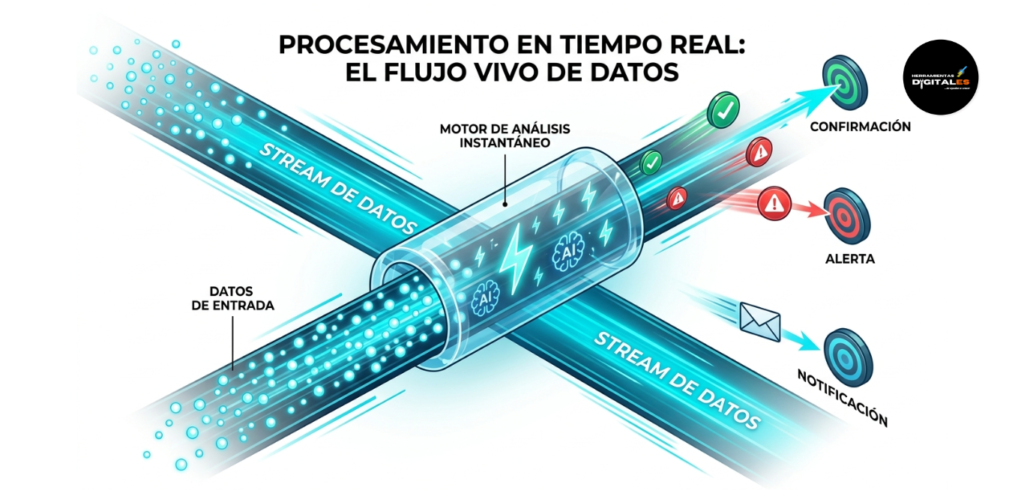
Importancia: Para un entorno de IA Operativa, el tiempo real es vital porque permite la acción proactiva. No sirve de nada saber que un cliente tuvo un problema ayer; necesitas que tu sistema detecte el error en el segundo 1 y active una compensación o una solución automática. Es la tecnología que permite que los sistemas sean «conscientes» del presente, garantizando una transparencia operativa total y una ventaja competitiva basada en la inmediatez.
Dato de valor: El tiempo real transforma los datos de «historia» en «noticias». Un sistema que procesa en tiempo real no mira el espejo retrovisor; mira el camino que tiene delante. Esto permite que la precisión técnica de tus modelos de IA se aplique al contexto exacto que el usuario está viviendo en este preciso momento.
Ejemplo práctico: Detección de Fraude en Pagos:
Evento: Un usuario intenta realizar una compra inusual.
Procesamiento: El flujo de datos llega al motor de procesamiento en tiempo real.
Análisis IA: Un modelo de IA compara la ubicación, el monto y el comportamiento en milisegundos.
Respuesta: La transacción se bloquea o se aprueba antes de que el cliente vea la pantalla de «Procesando», evitando el fraude sin afectar la experiencia del usuario.
Conclusiones: El Futuro es de los Sistemas Autónomos
La transición hacia una empresa impulsada por la IA no es un proyecto de software, es una evolución arquitectónica. Al integrar los cinco pilares que hemos analizado, las organizaciones dejan de ser reactivas para convertirse en entidades proactivas y resilientes.
Puntos clave para recordar:
De la Automatización a la Autonomía: Ya no basta con automatizar tareas repetitivas; el objetivo es delegar decisiones complejas a Agentes Autónomos capaces de razonar y actuar.
La Conectividad es el Sistema Nervioso: Sin una arquitectura de APIs REST y una comunicación Dirigida por Eventos (EDA), la IA permanece aislada. La verdadera potencia surge cuando los sistemas «hablan» e interactúan en tiempo real.
Datos como Combustible de Alta Calidad: La gestión mediante Pipelines y procesos ETL/ELT garantiza que la IA no solo reciba datos, sino que reciba inteligencia pura, libre de errores y lista para ser procesada.
Velocidad y Resiliencia como Diferenciadores: El Edge Computing y el Procesamiento en Tiempo Real son los que permiten que la tecnología se sienta humana, respondiendo a las necesidades del mercado y del cliente en el instante exacto en que surgen.
¿Te resultó útil?, aquí más glosarios:

Dominando la IA Generativa Avanzada: Glosario Técnico – Parte 2

Glosario Maestro de IA Generativa: Guía Definitiva para usuarios de IA – Parte 1