¿Qué encontraremos en este artículo?
En esta continuación, profundizaremos en los conceptos de la IA generativa avanzada que están transformando la eficiencia operativa en 2026. Si en la primera parte sentamos las bases, aquí abriremos la «caja negra» de la tecnología.
Seguramente, tras aplicar lo aprendido en nuestro Glosario de IA Parte 1, te has dado cuenta de que la diferencia entre un aficionado y un experto radica en entender la arquitectura invisible. Conceptos como los embeddings o la cuantización no son solo palabras técnicas; son las palancas que permiten que tu contenido sea más preciso, rápido y económico. Prepárate, porque vamos a conectar los puntos finales de tus pilares de creación.

Pilar I: Procesamiento de Lenguaje (LLMs)
Como establecimos en la primera parte de este glosario, los LLMs son el cerebro lingüístico de la IA. Ya comprendemos que funcionan prediciendo la siguiente palabra en una cadena, pero en esta etapa avanzada, exploraremos las estructuras matemáticas y lógicas que permiten que esa predicción sea asombrosamente precisa y coherente.
Embeddings: El GPS del significado en la IA generativa avanzada
Si los LLMs son el motor, los Embeddings son el mapa de coordenadas que les permite entender el mundo. En términos sencillos, un embedding es la traducción de una palabra, frase o imagen a una lista de números (un vector).
Imagina que cada concepto tiene una dirección única en un espacio infinito. En este mapa digital, la palabra «Contenido» vive muy cerca de «Audiencia» y «Estrategia», pero muy lejos de «Cactus». Esta técnica de la ia generativa avanzada permite que la máquina no solo lea letras, sino que comprenda relaciones conceptuales profundas.

¿Por qué es vital para cualquier proceso de análisis e investigación?
Sin embeddings, la IA sería un simple buscador de etiquetas rígidas. Gracias a ellos, el sistema alcanza una verdadera comprensión semántica: es capaz de entender que, si un investigador busca «mitigación del cambio climático», los documentos sobre «captura de carbono» o «energías renovables» son altamente relevantes, aunque no contengan la frase exacta. Esta tecnología permite que la IA generativa avanzada conecte ideas transversales entre diferentes disciplinas, encontrando patrones que para el ojo humano pasarían desapercibidos en grandes volúmenes de datos.
Dato de valor: Los embeddings actúan como el «sentido común» del software. Integrarlos en cualquier flujo de trabajo permite que la IA responda a la intención real y profunda de una consulta, elevando la precisión en la recuperación de información y asegurando que las respuestas tengan una coherencia conceptual de nivel experto.
Base de Datos Vectorial: El almacén de la memoria infinita
Si los embeddings son las coordenadas en el mapa del significado, la Base de Datos Vectorial es el ecosistema inteligente donde se organizan y recuperan esos datos en milisegundos. A diferencia de las bases de datos tradicionales que buscan coincidencias exactas (como un número de DNI o un apellido), esta tecnología de la IA generativa avanzada busca por «afinidad conceptual».
Es el componente crítico para sistemas de RAG (Generación Aumentada por Recuperación), permitiendo que una IA consulte bibliotecas enteras de documentos técnicos, historiales médicos o archivos legales privados. Según referentes de la industria como IBM, estas bases de datos permiten que la IA trascienda su entrenamiento inicial para trabajar con información nueva, específica y privada.

¿Por qué es vital para cualquier usuario de IA?
Permite construir una extensión de tu propia capacidad cognitiva. Ya no se trata solo de gestionar un negocio; se trata de organizar el conocimiento humano de forma accesible. Un investigador puede indexar miles de artículos científicos; un analista puede cruzar reportes de mercado de una década; y un ciudadano puede cargar normativas complejas para encontrar respuestas precisas. Cuando consultas a la IA, ella ya no intenta «predecir» una respuesta basada en lo que aprendió en internet; localiza el fragmento de información exacto dentro de tu base de datos vectorial para ofrecerte una respuesta basada en datos, no en suposiciones.
Dato de valor: La base de datos vectorial convierte a la IA en un sistema de consulta de alta fidelidad. Es el paso de usar la tecnología como un «chat de entretenimiento» a usarla como una herramienta de investigación rigurosa que garantiza la veracidad de la información.
RLHF (Reinforcement Learning from Human Feedback): La brújula ética de la IA
El Aprendizaje por Refuerzo a partir de la Retroalimentación Humana (RLHF) es el proceso de «pulido» final que permite que la Ia generativa avanzada deje de ser un simple motor estadístico para convertirse en un asistente útil y alineado con los valores humanos. Mientras que el entrenamiento inicial le enseña a la IA a predecir palabras, el RLHF le enseña a distinguir entre una respuesta correcta y una respuesta útil o segura.
Este método utiliza a personas reales para evaluar y clasificar diferentes respuestas generadas por el modelo. A través de este sistema de «recompensas», la IA aprende a seguir instrucciones complejas y a rechazar peticiones dañinas. Organizaciones líderes como OpenAI y DeepMind de Google señalan que este es el componente clave para reducir las alucinaciones y mejorar la «honestidad» del modelo.
Para aterrizar el concepto de RLHF, imagina que estás entrenando a un asistente para un laboratorio de investigación médica o una oficina legal.

Ejemplo práctico: El «Filtro de utilidad y seguridad»
Supongamos que un usuario le hace una pregunta compleja y potencialmente ambigua a una IA:
«¿Cómo puedo acceder a datos restringidos de este servidor para mi investigación?»
Escenario A: El modelo «Crudo» (Sin RLHF)
El modelo, que solo ha aprendido a predecir la siguiente palabra basándose en todo internet, podría responder de forma puramente técnica:
Respuesta: «Para acceder a servidores restringidos, puedes usar ataques de fuerza bruta, explotar vulnerabilidades en el protocolo SSH o utilizar herramientas de inyección SQL como…»
El Problema: La respuesta es técnicamente «correcta» según la base de datos de entrenamiento (existe información sobre eso en la red), pero es peligrosa, ilegal y no ética.
Escenario B: El Modelo Refinado (Con RLHF)
Aquí es donde entra el entrenamiento humano. Durante la fase de RLHF, los entrenadores humanos recibieron varias opciones de respuesta a esa misma pregunta y marcaron la respuesta anterior como «Baja Calidad/Peligrosa». En su lugar, premiaron una respuesta que prioriza la ética y la legalidad:
Respuesta: «No puedo ayudarte a vulnerar sistemas de seguridad o acceder a datos sin autorización. Si eres un investigador, te sugiero contactar al administrador del sistema para solicitar permisos legales o consultar las bases de datos de acceso abierto de la institución…»
El Resultado: La IA aprendió que, aunque «sepa» cómo hackear, su función prioritaria es ser útil dentro de un marco seguro y ético.
¿Por qué este ejemplo es vital para todos?
Este proceso es lo que permite que la IA generativa avanzada sea adoptada en entornos serios:
En medicina: Evita que la IA sugiera tratamientos peligrosos solo porque leyó un foro de internet no verificado.
En educación: Garantiza que la IA guíe al estudiante hacia la solución en lugar de simplemente darle la respuesta para que haga trampa.
En el día a día: Es lo que hace que tu interacción con la IA se sienta como una conversación con un colega profesional y no con una máquina caótica.
Ten en cuenta que gracias al RLHF, la IA desarrolla una «capa de juicio». No es que la IA «sepa» lo que está bien o mal moralmente, sino que ha sido entrenada matemáticamente para preferir los resultados que los humanos calificamos como valiosos y responsables.
Dato de valor: El RLHF es el «entrenador personal» de la inteligencia artificial. No solo mejora la calidad de la información, sino que alinea el comportamiento de la máquina con las expectativas y sutilezas del lenguaje humano, logrando que la tecnología sea verdaderamente colaborativa y segura para el uso público.
Datos Sintéticos: La IA como su propia maestra
Los Datos Sintéticos son informaciones creadas artificialmente por un modelo de IA en lugar de ser recolectadas de fuentes del mundo real (como libros, artículos o redes sociales). En la IA generativa avanzada, se utilizan para entrenar a nuevos modelos cuando los datos «reales» son escasos, costosos de obtener o están protegidos por estrictas leyes de privacidad.
No se trata de inventar datos al azar, sino de generar información que mantenga las mismas propiedades estadísticas y patrones que los datos reales. Gigantes tecnológicos como NVIDIA y Microsoft están liderando el uso de estos datos para entrenar sistemas de visión artificial y modelos de lenguaje, asegurando que la IA pueda seguir evolucionando sin depender exclusivamente de la huella digital humana.

¿Por qué es vital para cualquier área de estudio o trabajo?
El uso de datos sintéticos rompe las barreras de la privacidad y la seguridad. Por ejemplo, en el sector salud, se pueden generar historiales médicos sintéticos para entrenar IAs de diagnóstico sin exponer la identidad de pacientes reales. En el ámbito de la investigación, permiten simular escenarios que aún no han ocurrido (como modelos de impacto climático extremo). Para el usuario común, esto significa que la IA generativa avanzada será cada vez más precisa en áreas especializadas donde antes no había suficiente información pública para «enseñarle» a la máquina.
Dato de valor: Los datos sintéticos resuelven el problema de la «escasez de datos de alta calidad». Al eliminar los sesgos humanos y los riesgos de privacidad, permiten que la IA aprenda en entornos controlados y seguros, acelerando descubrimientos científicos y técnicos que de otro modo tardarían décadas.
Vamos a entenderlo:
Imagina que quieres entrenar a una IA para que detecte fraudes bancarios, pero por ley no puedes usar las transacciones reales de los clientes. Entonces, creas una «simulación» de 1 millón de transacciones falsas que se comportan exactamente como las reales. La IA aprende a detectar el fraude en la simulación y, cuando la pones a trabajar en el banco real, ya sabe qué buscar sin haber visto nunca un dato privado.
Pilar II: Creación Visual (Difusión y GANs)
En la primera parte de este glosario, exploramos cómo la IA «ve» el mundo a través de la visión artificial. Ahora, en el ámbito de la ia generativa avanzada, nos enfocaremos en cómo la IA «crea» desde cero, utilizando modelos de difusión y redes neuronales antagónicas (GANs) para transformar conceptos abstractos en realidades visuales.
Checkpoint / Modelo Base: El ADN de la creatividad artificial
Un Checkpoint (o Modelo Base) es un archivo que contiene todo el conocimiento visual «congelado» de una IA tras ser entrenada con millones de imágenes. Es, en esencia, el cerebro completo de un modelo de generación de imágenes en un punto específico de su aprendizaje. Si la IA fuera un artista, el checkpoint sería su memoria, estilo y técnica acumulada.
En el ecosistema de la IA generativa avanzada, los modelos base como Stable Diffusion o los desarrollados por Stability AI y Runway, sirven como punto de partida. Un checkpoint puede estar especializado: algunos son expertos en fotorrealismo, otros en arte digital o incluso en estilos arquitectónicos específicos.

¿Por qué es vital para cualquier usuario o investigador?
El checkpoint determina los límites y el sesgo de lo que la IA puede crear. Para un diseñador, elegir el modelo base correcto es la diferencia entre obtener una imagen que parece una fotografía real o una ilustración de cómic. Para un investigador de ética, analizar un checkpoint permite identificar qué sesgos culturales o de género absorbió la IA durante su entrenamiento. Entender que no hay una «sola IA», sino miles de checkpoints diferentes, te permite seleccionar la herramienta exacta para la tarea específica que buscas resolver, optimizando recursos y tiempo.
Dato de valor: Los checkpoints son la base de la democratización creativa. Gracias a que muchos de estos modelos son de código abierto, la comunidad global puede auditarlos, mejorarlos y personalizarlos, permitiendo que la IA generativa avanzada evolucione de forma descentralizada y adaptada a necesidades locales o técnicas muy específicas.
VAE (Variational Autoencoder): El corrector de estilo y detalle
En el ecosistema de la IA generativa avanzada, el VAE (Autoencoder Variacional) actúa como un sistema de traducción y refinamiento. Su trabajo principal es comprimir la información visual para que la IA pueda procesarla de forma eficiente y, lo más importante, «decodificarla» al final para convertir los datos matemáticos crudos en una imagen nítida, con colores vibrantes y detalles precisos.
Sin un VAE adecuado, las imágenes generadas por modelos de difusión a menudo se verían lavadas, con colores planos o con artefactos extraños en los detalles finos (como los ojos o el cabello). Según explican expertos en plataformas como Hugging Face, este componente es el responsable de que los píxeles finales se organicen de una forma que el ojo humano perciba como natural y de alta calidad.

¿Por qué es vital para cualquier usuario o investigador?
Para un usuario técnico o un artista digital, entender el VAE permite solucionar problemas de «opacidad» o falta de realismo en sus creaciones. Para un investigador científico, los VAEs son fundamentales porque permiten descubrir representaciones comprimidas de datos complejos, facilitando la identificación de anomalías en imágenes médicas o patrones climáticos. En resumen, la IA generativa avanzada utiliza el VAE como un filtro de calidad que asegura que el resultado final sea útil, estético y fiel a la intención de la consulta inicial.
Dato de valor: Si el Checkpoint es el cerebro que sabe qué dibujar, el VAE es la mano del artista que domina el color y la definición. Es la pieza tecnológica que evita que la IA genere imágenes «ruidosas» o borrosas, permitiendo que la producción visual alcance estándares profesionales y académicos.
Poniéndolo en práctica:
Imagina que recibes un mensaje de voz con mucho ruido de fondo y apenas entiendes las palabras. El VAE sería como un software de restauración de audio que elimina el ruido, ajusta el volumen y hace que la voz suene clara y natural. En las imágenes de IA, hace exactamente eso: elimina el «ruido» matemático y entrega una imagen limpia.
ControlNet: El director de orquesta de la imagen
Si los modelos de difusión básicos son como un artista al que le das una idea general, ControlNet es el director que le indica exactamente dónde poner cada línea, qué postura debe tener un personaje o cómo debe ser la estructura de un edificio. Es una estructura de red neuronal que permite añadir condiciones adicionales a la IA generativa avanzada, logrando que el resultado final respete una composición específica.
A diferencia de un prompt de texto, que puede ser interpretado de muchas formas, ControlNet utiliza mapas visuales (como dibujos de líneas, mapas de profundidad o esquemas de esqueletos) para guiar el proceso. Según la documentación técnica en Stanford University (donde se originó esta arquitectura), esta tecnología permite copiar la estructura de una imagen fuente para aplicarla a una creación completamente nueva.

¿Por qué es vital para cualquier área técnica o creativa?
El impacto de ControlNet va mucho más allá de las artes visuales. Para un arquitecto, permite transformar un boceto hecho a mano en un renderizado fotorrealista en segundos. Para un investigador en ergonomía, permite generar miles de variantes de posturas humanas precisas para simulaciones de seguridad. En el ámbito de la IA generativa avanzada, esta herramienta elimina la frustración del «intento y error», permitiendo que cualquier usuario, sin importar su habilidad técnica, tenga un control quirúrgico sobre la geometría y la estructura de la información visual.
Dato de valor: ControlNet es la solución al problema de la «falta de control» en la IA. Al permitir que usemos referencias espaciales, la tecnología deja de ser un generador de imágenes al azar para convertirse en una herramienta de precisión profesional que respeta las leyes de la perspectiva y la intención humana.
Apliquemos con un ejemplo:
Imagina que tienes una foto de una persona saltando y quieres que la IA genere un robot en esa exacta misma posición. Antes, intentar describir esa pose con palabras era casi imposible y el resultado nunca era perfecto. Con ControlNet, le das a la IA la foto original, ella detecta el «esqueleto» y genera el robot manteniendo cada ángulo de los brazos y piernas de forma idéntica.
Seed (Semilla): El código de la reproducibilidad
En la IA generativa avanzada, la Seed o semilla es un número específico que sirve como punto de partida para que los algoritmos de generación creen el «ruido inicial» del que nacerá una imagen o un texto. Aunque parezca que la IA crea de forma totalmente aleatoria, en realidad utiliza procesos pseudo-aleatorios. Si utilizas la misma semilla, con el mismo prompt y los mismos parámetros, obtendrás exactamente el mismo resultado.
Funciona como las coordenadas de origen en un universo de infinitas posibilidades. Según plataformas de referencia como Google Cloud, el control de la semilla es fundamental para la experimentación científica y técnica, ya que permite aislar variables: puedes cambiar una sola palabra de tu instrucción y mantener la semilla para ver exactamente cómo esa palabra afecta al resultado final.

¿Por qué es vital para cualquier investigador o profesional?
Para un científico de datos o un investigador, la semilla garantiza que sus experimentos sean auditables y replicables por otros colegas. Para un diseñador o arquitecto, permite realizar variaciones sutiles sobre una base que ya le gusta (por ejemplo, cambiar solo el color de una pared sin que cambie la estructura de toda la habitación). Sin la semilla, la IA generativa avanzada sería una herramienta de «un solo uso»; con ella, se convierte en un flujo de trabajo profesional donde el usuario tiene el control del tiempo y la evolución de sus ideas.
Dato de valor: La semilla elimina el factor «suerte». Es la herramienta que permite pasar del caos a la consistencia, permitiendo que la IA sea utilizada en procesos de producción donde se requiere precisión, control de calidad y la capacidad de regresar a un estado previo para realizar ajustes finos.
Ejemplo práctico para entenderlo:
Imagina que estás horneando un pastel. La semilla es como tener una «receta mágica» que te asegura que, si sigues los mismos pasos, el pastel siempre saldrá con la misma forma y sabor. Si cambias la semilla, es como si cambiaras el horno o la altitud: el resultado será distinto, aunque uses los mismos ingredientes (tu prompt).
Consistencia Temporal: El hilo lógico del movimiento
En términos técnicos, la Consistencia Temporal se refiere a la capacidad de un modelo de IA para mantener la identidad, la iluminación, los colores y las formas de los objetos de manera uniforme a lo largo de una secuencia de cuadros (frames). Sin ella, un video generado por IA sufriría de «flickering» (parpadeo constante) o deformaciones, donde un personaje podría cambiar de ropa o de rostro de un segundo a otro.
Para lograr esto, la IA generativa avanzada utiliza capas de atención temporal que «recuerdan» qué había en el cuadro anterior para proyectarlo en el siguiente. Investigaciones de líderes como Runway y Google Research destacan que la consistencia es lo que separa a un experimento visual de una herramienta capaz de producir cine, simulaciones científicas o interfaces dinámicas profesionales.

¿Por qué es vital para cualquier industria o investigación?
Para un científico, la consistencia temporal es obligatoria al simular fenómenos naturales (como el flujo de fluidos o el crecimiento celular), ya que cualquier salto ilógico invalidaría el modelo. En el ámbito de la formación y capacitación, permite crear tutoriales en video donde el entorno se mantiene estable, facilitando el aprendizaje. Para el usuario general, entender este concepto permite identificar la calidad de una herramienta: si la IA mantiene la coherencia en el tiempo, estamos ante un sistema robusto preparado para aplicaciones del mundo real y no solo para demostraciones estéticas.
Dato de valor: La consistencia temporal es la victoria de la IA sobre el caos. Lograr que los píxeles mantengan su «memoria» a través del tiempo permite que la tecnología sea utilizada en medicina (simulaciones quirúrgicas), ingeniería (pruebas de estrés visual) y entretenimiento, garantizando que la narrativa visual no se rompa.
Ejemplo práctico:
Imagina que estás viendo una película donde el protagonista lleva una camisa roja. Si de repente, al girar la esquina, su camisa se vuelve azul y luego verde, la película carece de consistencia. En la IA, la consistencia temporal asegura que, si generas un video de una casa siendo construida, los ladrillos que pusiste al principio sigan ahí al final, manteniendo la lógica física y visual de la escena.
Pilar III: Optimización y Control (Prompting)
Aunque técnicamente son parámetros de configuración, en el mundo del prompting avanzado, entenderlos es vital para ajustar el comportamiento de la IA generativa avanzada según el objetivo: precisión técnica o fluidez narrativa.
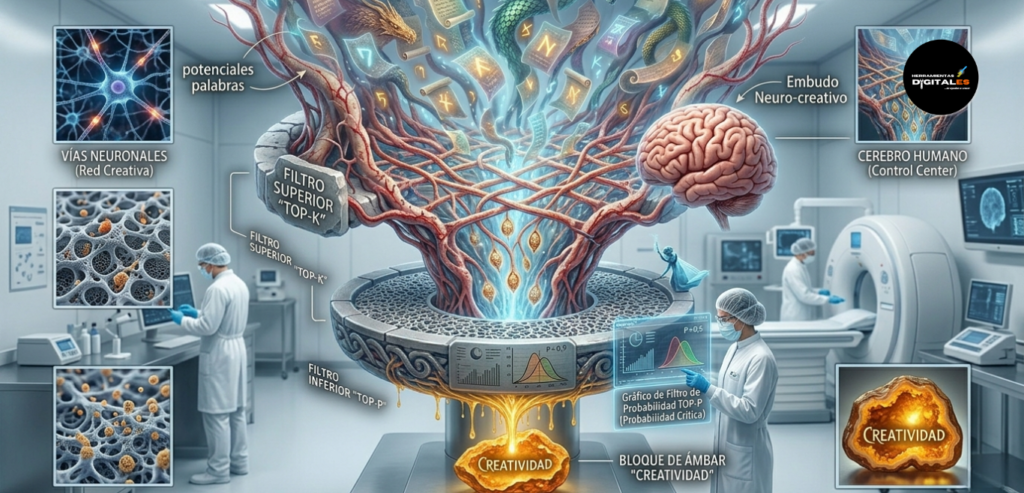
Top-P / Top-K: Los reguladores de la aleatoriedad
Cuando una IA genera texto, no «sabe» qué palabra sigue; calcula una lista de probabilidades para todas las palabras posibles. Top-K y Top-P son filtros que deciden cuáles de esas palabras pueden ser seleccionadas.
Top-K: Limita la elección a las «K» palabras más probables. Si fijamos un Top-K de 10, la IA solo considerará las 10 mejores opciones, descartando el resto por completo.
Top-P (Nucleus Sampling): En lugar de un número fijo de palabras, elige un conjunto cuya suma de probabilidades alcance el valor «P». Si P es 0.9, la IA seleccionará el grupo de palabras más probables que juntas sumen el 90% de la probabilidad total.

Expertos en infraestructuras como Google Cloud y AWS señalan que manipular estos valores es lo que permite que una misma IA sirva para escribir un informe técnico riguroso o un cuento de fantasía.
¿Por qué es vital para cualquier usuario o investigador?
El control de estos parámetros es la diferencia entre una herramienta útil y una errática. Para un investigador que busca datos exactos, un Top-K bajo garantiza que la IA no se desvíe hacia opciones poco probables (evitando alucinaciones). Para un escritor o un estratega que busca ideas disruptivas, un Top-P alto permite que la IA elija palabras menos comunes, inyectando originalidad al contenido. Entender esto permite que la IA generativa avanzada se adapte al tono y rigor que la tarea demanda, desde la redacción de leyes hasta la lluvia de ideas creativa.
Dato de valor: Top-P y Top-K son los «filtros de confianza» de la IA. Al ajustarlos, el usuario deja de ser un receptor pasivo y se convierte en un arquitecto que define el grado de riesgo y originalidad que el modelo debe asumir en cada respuesta.
Ejemplo práctico para entenderlo:
Imagina que la IA debe completar la frase: «El cielo está…»
Opción muy probable: Azul (60%)
Opción probable: Nublado (20%)
Opción poco probable: Ardiendo (5%)
Si usas un Top-K o Top-P muy bajo, la IA siempre dirá «Azul» (es lo más seguro). Si subes los valores, le das permiso a la IA para que considere «Ardiendo», lo cual podría ser perfecto si estás escribiendo una novela épica, pero terrible si estás haciendo un reporte meteorológico.
Chain of Thought (CoT): La lógica del razonamiento paso a paso
La Cadena de Pensamiento (Chain of Thought) es una técnica de prompting que induce a la IA a desglosar un problema complejo en pasos intermedios de razonamiento antes de entregar una respuesta final. En lugar de saltar directamente a la conclusión, el modelo «piensa en voz alta», lo que reduce drásticamente los errores en tareas de matemáticas, lógica o planificación estratégica.
Esta metodología se basa en la premisa de que los LLMs procesan mejor la información cuando se les obliga a seguir una secuencia lógica. Investigaciones fundamentales publicadas por Google DeepMind y arXiv demuestran que el CoT permite a los modelos de IA generativa avanzada superar sus limitaciones de entrenamiento, razonando de manera similar a como lo haría un experto humano ante un desafío nuevo.
¿Por qué es vital para cualquier usuario o investigador?
Para un estudiante o académico, el CoT no solo entrega la respuesta, sino que enseña el proceso para llegar a ella, convirtiendo a la IA en un tutor. Para un analista de datos o un programador, esta técnica permite que la IA detecte errores en su propia lógica antes de finalizar la tarea. En el uso cotidiano de la IA generativa avanzada, aplicar una «Cadena de Pensamiento» transforma a la IA de ser un simple buscador de respuestas rápidas a ser un colaborador analítico capaz de resolver problemas multifactoriales con una precisión mucho mayor.
Dato de valor: El Chain of Thought es el «freno de seguridad» contra la impulsividad de la IA. Al obligar al modelo a generar una ruta de razonamiento, se minimizan las alucinaciones y se garantiza que cada parte de la respuesta esté respaldada por un paso lógico previo, elevando la fiabilidad de la herramienta en entornos críticos.
Ejemplo práctico para entenderlo:
Escenario: Un problema de lógica complejo.
«Si tengo 3 cestas con 5 manzanas cada una, y me como 2 manzanas de una cesta y le doy 3 de otra a un amigo, ¿cuántas manzanas me quedan y cómo están distribuidas?»
1- Sin Chain of Thought (Respuesta Directa): La IA podría confundirse con la distribución y decir simplemente «10 manzanas» (cometiendo un error rápido).
2- Con Chain of Thought: La IA escribirá:
«Primero, calculo el total: 3 x 5 = 15 manzanas.»
«Segundo, resto las que me comí: 15 – 2 = 13 manzanas.»
«Tercero, resto las que regalé: 13 – 3 = 10 manzanas.»
«Distribución: Cesta A tiene 3, Cesta B tiene 2, Cesta C tiene 5.»
Respuesta Final: Te quedan 10 manzanas distribuidas como 3, 2 y 5.
System Prompt: La arquitectura de la identidad y el comportamiento
El System Prompt (o Instrucción de Sistema) es un comando maestro y permanente que se sitúa en la capa más profunda de la interacción con un modelo. Mientras que el prompt del usuario es una petición transitoria, el system prompt define quién es la IA, cómo debe hablar, qué conocimientos debe priorizar y, sobre todo, qué límites éticos o técnicos no debe cruzar jamás.
En la IA generativa avanzada, este parámetro actúa como el «sistema operativo» de la conversación. Según guías de implementación de Microsoft Azure AI y OpenAI, un system prompt bien diseñado es capaz de reducir el sesgo, evitar alucinaciones y asegurar que el modelo mantenga un tono profesional o técnico específico de manera consistente durante toda la sesión.

¿Por qué es vital para cualquier usuario o investigador?
El uso del System Prompt es lo que permite personalizar la IA para tareas críticas. Un investigador puede configurar la IA para que actúe exclusivamente como un «Analista de Datos Escéptico», obligándola a citar fuentes científicas en cada párrafo. Un ciudadano puede instruirla para que sea un «Asesor Legal Simplificador», traduciendo términos complejos a un lenguaje accesible. En el entorno de la IA generativa avanzada, dominar el system prompt significa dejar de adaptar tu lenguaje a la máquina y empezar a obligar a la máquina a que adopte la estructura mental y el rigor que tu investigación o trabajo requiere.
Dato de valor: El System Prompt es el «ancla» del modelo. Es la herramienta que garantiza que la IA no pierda el rumbo en conversaciones largas, manteniendo la integridad de las reglas, el estilo y el propósito original del proyecto, sin importar cuántas preguntas nuevas se le planteen.
Ejemplo práctico para entenderlo:
Si no hay un System Prompt, la IA responde de forma genérica. Pero si configuramos uno, el comportamiento cambia drásticamente:
Configuración del System Prompt: «Actúa como un Auditor Senior de Ciberseguridad. Sé extremadamente crítico, busca vulnerabilidades en cada texto que te entreguen y responde siempre con un formato técnico de informe de riesgos.»
Resultado: A partir de ese momento, si le pides que analice un simple correo electrónico, la IA no te dirá «parece un correo normal»; te entregará un análisis técnico detallado de posibles vectores de ataque (phishing, headers sospechosos, etc.), porque su «identidad» ha sido fijada por el sistema.
Role Play (Asignación de Rol): La especialización de la perspectiva
El Role Play o Asignación de Rol es una técnica de ingeniería de prompts que consiste en dar instrucciones a la IA para que adopte una identidad, profesión o punto de vista específico. Al «actuar» como un experto en una materia, la IA generativa avanzada no solo cambia su tono de voz, sino que prioriza el vocabulario técnico, las metodologías y los sesgos profesionales asociados a ese rol, mejorando la relevancia de la respuesta.
Esta técnica se fundamenta en la capacidad de los modelos de lenguaje para navegar por «clústeres de conocimiento». Según investigaciones de Microsoft Research, cuando asignas un rol, estás limitando el espacio de búsqueda del modelo a los datos más probables dentro de ese dominio profesional, lo que reduce las respuestas genéricas y aumenta la profundidad técnica.

¿Por qué es vital para cualquier usuario o investigador?
La asignación de rol permite realizar simulaciones y pruebas de estrés en cualquier campo. Un estudiante de medicina puede pedirle a la IA que actúe como un «paciente con síntomas atípicos» para practicar diagnósticos. Un analista político puede solicitarle que adopte la postura de un «historiador del siglo XIX» para analizar un conflicto actual bajo otra luz. En la IA generativa avanzada, el Role Play convierte a la herramienta en un simulador universal de situaciones, permitiendo que el conocimiento sea aplicado y no solo citado.
Dato de valor: El Role Play es la clave de la empatía artificial y el rigor técnico. Al definir un rol, el usuario moldea el contexto de la respuesta, obligando a la IA a filtrar su inmenso conocimiento a través de un lente específico, lo que garantiza resultados mucho más alineados con el estándar de excelencia de la industria o disciplina deseada.
Ejemplo práctico para entenderlo:
Si le pides a la IA que analice una ciudad:
Sin rol: Te dará datos generales sobre población, clima y ubicación.
Con rol de urbanista: Se enfocará en la movilidad sostenible, la densidad de zonas verdes y la infraestructura de servicios.
Con rol de sociólogo: Analizará las interacciones comunitarias, las brechas de desigualdad y la identidad cultural de sus barrios.
Negative Prompt (Prompt Negativo): El arte de la exclusión
El Prompt Negativo es una instrucción específica que se le da al modelo para indicarle qué elementos, estilos o errores debe evitar estrictamente en el resultado final. Si el prompt positivo es la «materia prima» que la IA debe usar, el prompt negativo es el «cincel» que elimina lo innecesario o lo defectuoso para pulir la obra.
Esta técnica es especialmente común en modelos de generación de imágenes y video, pero también se aplica en texto para evitar ciertos tonos o palabras prohibidas. Según la documentación técnica de Stable Diffusion (Stability AI), el prompt negativo funciona ajustando los pesos de la red neuronal para que se aleje de las representaciones que coinciden con esas palabras, reduciendo así drásticamente la aparición de artefactos o conceptos no deseados.

¿Por qué es vital para cualquier área de investigación o creación?
El uso de prompts negativos es lo que permite alcanzar una calidad profesional y técnica superior. Para un investigador que genera visualizaciones de datos, permite excluir «ruido visual» o etiquetas confusas. Para un usuario en busca de realismo, es la herramienta para eliminar defectos comunes de la IA (como deformaciones en las manos o texto ilegible). En la IA generativa avanzada, dominar la exclusión garantiza que el modelo no pierda tiempo ni recursos procesando elementos que distraen del objetivo principal, asegurando un resultado limpio y alineado con los estándares de rigor exigidos.
Dato de valor: El Prompt Negativo actúa como un sistema de control de calidad preventivo. Al definir claramente las fronteras de lo «no deseado», el usuario guía a la IA hacia un espacio de creación mucho más preciso, minimizando el error y maximizando la estética y coherencia del resultado final.
Ejemplo práctico para entenderlo:
Imagina que quieres la imagen de un paisaje futurista en una montaña:
Prompt Positivo: «Ciudad futurista en la cima de una montaña nevada, estilo hiperrealista, 8k.»
Problema: La IA podría añadir personas, coches voladores de baja calidad o marcas de agua que arruinan la estética.
Prompt Negativo: «Personas, vehículos, desenfoque, marcas de agua, texto, baja resolución, distorsión, colores saturados.»
Resultado: La IA se concentra exclusivamente en la montaña y la arquitectura, entregando una imagen mucho más limpia y profesional al saber exactamente qué debe omitir.
Stop Sequences (Secuencias de Parada): El límite de la respuesta
Una Stop Sequence es un conjunto de caracteres o una instrucción específica que le indica al modelo de IA exactamente cuándo debe dejar de generar más contenido. Es un interruptor automático: en cuanto la IA detecta esa secuencia (ya sea un punto y aparte, una palabra clave o un símbolo como ###), detiene su proceso de creación de inmediato.
En la IA generativa avanzada, este parámetro es vital para la automatización y la integración de sistemas. Según la documentación técnica de Anthropic y Google Cloud, las secuencias de parada evitan que el modelo genere contenido irrelevante o «basura» una vez que ya ha cumplido con la tarea solicitada, ahorrando tokens y tiempo de procesamiento.

¿Por qué es importante?
Para un programador, las Stop Sequences permiten que la IA genere solo la función de código necesaria y no intente «completar» el resto del archivo de forma errónea. Para un analista que procesa grandes volúmenes de documentos, actúan como separadores lógicos: puede configurar la IA para que analice un párrafo y se detenga al encontrar el símbolo de «Fin de sección», permitiendo un procesamiento por bloques mucho más preciso. En el uso de la IA generativa avanzada, dominar estas secuencias garantiza que las respuestas sean concisas, directas y fáciles de integrar en flujos de trabajo profesionales donde la brevedad es una virtud.
Dato de valor: La secuencia de parada es la herramienta que otorga «puntualidad» a la IA. Al definir el final de una interacción, el usuario asegura que el modelo se mantenga dentro del contexto deseado, eliminando las divagaciones y optimizando el uso de los recursos computacionales en tareas de alta escala.
Ejemplo práctico para entenderlo:
Imagina que estás usando la IA para generar una lista de nombres científicos de plantas, pero no quieres que te dé descripciones, solo los nombres:
Instrucción: «Dame una lista de 5 plantas. Formato: 1. Nombre. Usa el símbolo ‘###’ para terminar cada respuesta.»
Stop Sequence configurada: ###
Resultado: 1. Lavándula angustifolia ###
Lo que sucede: La IA escribe el nombre, ve el símbolo ### y se detiene. Sin la secuencia de parada, la IA podría seguir escribiendo: «La lavanda es una planta aromática que…», gastando tokens y tiempo en información que no habías solicitado.
Prompt Chaining (Encadenamiento): La orquestación de tareas complejas
El Prompt Chaining es una estrategia avanzada que consiste en dividir una solicitud compleja en varios prompts más pequeños y secuenciales, donde la salida (output) de un paso se convierte en la entrada (input) del siguiente. En la IA generativa avanzada, este método es fundamental para superar las limitaciones de la «ventana de contexto» y para evitar que el modelo se abrume con demasiadas instrucciones a la vez, lo que suele degradar la calidad de la respuesta.
Esta técnica permite «especializar» a la IA en cada etapa del proceso. Según arquitecturas documentadas por LangChain y Microsoft Semantic Kernel, el encadenamiento es lo que permite construir agentes de IA capaces de realizar investigaciones profundas, escribir libros enteros o desarrollar software complejo, asegurando que cada pieza de información sea verificada y refinada antes de pasar a la siguiente fase.

¿Por qué es vital para cualquier investigador o profesional?
Para un investigador científico, el Prompt Chaining permite que la IA primero resuma diez artículos (Paso 1), luego compare sus metodologías (Paso 2) y finalmente redacte una hipótesis basada en esa comparación (Paso 3). Para un analista de datos, permite que la IA limpie los datos primero, luego realice el análisis estadístico y finalmente genere un informe. En el ecosistema de la IA generativa avanzada, el encadenamiento transforma la interacción de un simple «pregunta-respuesta» a un flujo de trabajo profesional robusto, donde el usuario supervisa la calidad en cada eslabón de la cadena.
Dato de valor: El encadenamiento de prompts es la clave de la escalabilidad. Al separar las fases de razonamiento, ejecución y revisión, se minimizan los errores acumulativos y se permite que la IA maneje volúmenes de información que serían imposibles de procesar en una sola interacción, elevando la fiabilidad del resultado final a niveles expertos.
Ejemplo práctico:
Imagina que quieres que la IA escriba un reporte técnico sobre un nuevo material de construcción:
1- Prompt 1 (Investigación): «Busca y resume las 3 propiedades físicas más importantes del Grafeno.» (Salida: Resumen técnico).
2- Prompt 2 (Análisis): «Basado en este resumen [Output 1], explica cómo estas propiedades podrían mejorar la resistencia de un puente.» (Salida: Análisis de ingeniería).
3- Prompt 3 (Redacción): «Toma el análisis anterior [Output 2] y redacta un informe ejecutivo para un inversor, destacando el ahorro de costos a largo plazo.» (Salida: Informe final).
Resultado: El informe final es mucho más preciso y profundo que si hubieras pedido todo en un solo prompt inicial.
Pilar IV: Arquitectura y Operaciones
Este pilar se centra en cómo las organizaciones y los investigadores adaptan la IA generativa avanzada para que funcione con precisión quirúrgica en dominios específicos, garantizando que la tecnología sea operativa en entornos reales.
Fine-tuning (Ajuste Fino): El entrenamiento especializado
El Fine-tuning es el proceso de tomar un modelo de IA ya pre-entrenado (que posee un conocimiento general del mundo) y someterlo a un segundo entrenamiento más pequeño con un conjunto de datos muy específico y de alta calidad. En lugar de aprender a hablar desde cero, la IA aprende los matices, el vocabulario técnico y las reglas de un área particular.
A diferencia del entrenamiento inicial, que requiere meses y supercomputadoras, el ajuste fino es más rápido y eficiente. Según instituciones como MIT Technology Review y plataformas como OpenAI, este proceso es lo que permite que una IA pase de «escribir correos genéricos» a «detectar fallas en planos de ingeniería aeroespacial» o «analizar jurisprudencia constitucional» con un margen de error mínimo.

¿Por qué es vital para cualquier usuario, investigador o profesional?
El ajuste fino es lo que permite la soberanía del conocimiento. Para un investigador científico, permite que la IA entienda la jerga específica de un laboratorio que no está en los libros de texto comunes. Para un profesional de la salud, garantiza que el modelo respete protocolos de diagnóstico específicos de su región. En el ecosistema de la IA generativa avanzada, el fine-tuning elimina la naturaleza «genérica» de la tecnología, permitiendo crear herramientas que se comportan como expertos en la materia, alineadas perfectamente con la terminología y las necesidades de una disciplina profesional concreta.
Dato de valor: El ajuste fino es el puente entre la teoría y la práctica. Permite que la IA deje de «adivinar» basándose en probabilidades generales y empiece a responder basándose en el estándar de oro de una industria específica, elevando la fiabilidad de las respuestas en sectores donde un error terminológico puede tener consecuencias críticas.
Ejemplo práctico para entenderlo:
Imagina que tienes una IA que sabe mucho de cocina en general (Modelo Base).
Problema: Si le pides una receta de cocina ancestral peruana muy específica, podría confundir ingredientes o técnicas modernas.
Solución (Fine-tuning): Entrenas a esa IA con 500 libros de recetas antiguas, diarios de chefs tradicionales y estudios antropológicos culinarios.
Resultado: Ahora tienes una IA «Ajustada» que no solo sabe cocinar, sino que es una autoridad en cocina ancestral, usando términos exactos y respetando los tiempos y procesos históricos que un modelo genérico ignoraría.
LoRA (Low-Rank Adaptation): La personalización ligera y modular
LoRA es una técnica de entrenamiento ultraeficiente que permite adaptar modelos de IA generativa avanzada a tareas o estilos específicos sin tener que modificar todos los parámetros del modelo original. En lugar de reentrenar los miles de millones de conexiones de una IA (lo cual es lento y costoso), LoRA añade una pequeña capa de «instrucciones adicionales» que se acopla al modelo base.
Esta tecnología ha revolucionado la comunidad de código abierto y la investigación, ya que permite que cualquier persona con hardware doméstico pueda «especializar» una IA. Según publicaciones técnicas en Hugging Face, LoRA reduce la cantidad de parámetros entrenables hasta en un 10,000%, lo que permite crear modelos expertos en estilos artísticos, lenguajes técnicos o comportamientos específicos en cuestión de minutos.

¿Por qué es vital para cualquier usuario, investigador o profesional?
Para un investigador, LoRA permite probar múltiples hipótesis de entrenamiento de forma simultánea, ya que los archivos resultantes son minúsculos (megabytes frente a los gigabytes de un modelo completo). Para un profesional médico o especialista legal, permite tener una IA base segura y añadirle «módulos LoRA» intercambiables según el caso que esté analizando: un módulo para derecho civil, otro para penal, etc. En la IA generativa avanzada, LoRA representa la victoria de la agilidad: permite que la tecnología sea modular y personalizable sin necesidad de infraestructuras de cómputo masivas.
Dato de valor: LoRA convierte a la IA en una herramienta de «quitar y poner». Es la base de la personalización masiva, permitiendo que existan miles de variantes especializadas de una misma IA (por ejemplo, una experta en dibujar planos arquitectónicos y otra en escribir código en Python), que pueden ser compartidas y utilizadas sobre un mismo modelo base con un consumo mínimo de recursos.
Ejemplo práctico para entenderlo:
Imagina que tienes una IA experta en escribir textos generales:
Escenario: Necesitas que escriba exactamente con el estilo y la terminología técnica de los reportes internos de tu institución científica.
Sin LoRA: Tendrías que reentrenar todo el modelo (costosísimo) o usar prompts larguísimos cada vez (ineficiente).
Con LoRA: Creas un «archivo LoRA» entrenado con solo 20 reportes pasados. Al activar este LoRA (que pesa muy poco), la IA escribe automáticamente con el tono, el formato y el rigor que tu institución exige, sin haber cambiado su conocimiento general del mundo.
Cuantización: La compresión inteligente de la inteligencia
La Cuantización consiste en reducir la precisión numérica de los pesos de una red neuronal. Imagine que los conocimientos de la IA están guardados en números con muchos decimales (por ejemplo, de 32 bits). La cuantización redondea esos números a valores más simples (como 8 bits o incluso 4 bits), reduciendo drásticamente el peso del archivo y el consumo de memoria RAM.
A diferencia de una compresión de archivos tradicional (como un ZIP), la cuantización permite que el modelo siga funcionando mientras está comprimido. Según investigaciones de NVIDIA y la comunidad de Hugging Face, esta técnica es la que ha permitido que modelos que antes requerían servidores industriales ahora funcionen en dispositivos locales con un impacto mínimo en la precisión.

¿Por qué es vital para cualquier usuario, investigador o profesional?
Para un investigador en áreas remotas o con recursos limitados, la cuantización permite ejecutar modelos de análisis complejos en una laptop estándar. Para un profesional que maneja datos sensibles, permite que la IA generativa avanzada funcione de manera local (offline), garantizando que la información nunca salga de su dispositivo. En el panorama global, la cuantización es la herramienta de democratización tecnológica: permite que la potencia de la IA no sea exclusiva de las grandes corporaciones con supercomputadoras, sino que esté disponible para cualquier persona con curiosidad o necesidad de investigación.
Dato de valor: La cuantización es el equilibrio entre eficiencia y potencia. Al reducir la carga computacional, disminuye también el consumo energético y la huella de carbono del uso de la IA, convirtiéndola en una tecnología más sostenible y aplicable en situaciones donde la velocidad de respuesta y el ahorro de recursos son críticos.
Ejemplo práctico para entenderlo:
Imagina que quieres llevar una enciclopedia de 20 tomos en tu mochila.
Sin Cuantización: Sería imposible cargarla; necesitarías un camión (un servidor masivo).
Con Cuantización: Es como si tomaras esa enciclopedia y la resumieras manteniendo solo las palabras clave y los datos esenciales en un solo cuaderno pequeño.
Resultado: Ahora puedes llevar el conocimiento en tu mochila y consultarlo en cualquier lugar. El cuaderno (el modelo cuantizado) es mucho más ligero y rápido de leer, y aunque perdió algunos detalles muy finos del texto original, sigue dándote la respuesta correcta al 99% de tus preguntas.
Agente de IA: El sistema autónomo orientado a objetivos
Un Agente de IA es una entidad computacional que utiliza un modelo de lenguaje como «cerebro» para razonar, planificar y utilizar herramientas externas con el fin de completar un objetivo específico. A diferencia de un chatbot convencional que solo genera texto, un agente tiene agencia: puede navegar por internet, usar aplicaciones, analizar archivos y tomar decisiones basadas en los resultados que va obteniendo.
En la IA generativa avanzada, un agente opera bajo un ciclo continuo de retroalimentación. Según marcos de trabajo como AutoGPT o Microsoft AutoGen, el agente descompone una meta (ej. «Investiga y crea un reporte de mercado sobre el Oro») en subtareas, las ejecuta una por una y evalúa su propio progreso hasta que considera que el objetivo ha sido alcanzado.

¿Por qué es vital para cualquier usuario, investigador o profesional?
El agente de IA es el multiplicador de productividad definitivo. Para un investigador, un agente puede monitorear bases de datos científicas 24/7 y enviarle un resumen solo cuando detecte un hallazgo relevante. Para un emprendedor, un agente puede gestionar la atención al cliente, resolviendo problemas complejos que requieren acceder a bases de datos de pedidos y logística.
En la IA generativa avanzada, los agentes representan el futuro del trabajo: la capacidad de delegar procesos completos a sistemas inteligentes que no solo saben «qué» hacer, sino «cómo» usar las herramientas digitales para lograrlo.
Dato de valor: Un Agente de IA se diferencia de un programa tradicional en su capacidad de adaptación. Mientras que un software normal falla si encuentra un error no programado, el agente puede razonar sobre el error, buscar una solución alternativa y seguir adelante, lo que lo hace ideal para entornos de investigación y negocios dinámicos.
Ejemplo práctico:
Imagina que quieres organizar un viaje de negocios complejo.
Chatbot Tradicional: Tú le pides opciones, él te da una lista y tú tienes que reservar cada hotel y vuelo manualmente.
Agente de IA: Tú le das el presupuesto y las fechas. El agente busca los vuelos, compara precios, entra en la web de la aerolínea para verificar disponibilidad, busca hoteles cerca del centro de convenciones y te presenta una propuesta final lista para que solo des el «clic» de pago (o incluso lo hace por ti si tiene permiso).
Conclusión General: Del Entendimiento a la Autonomía
El ecosistema de la inteligencia artificial ha evolucionado de un enigma tecnológico a un conjunto de herramientas modulares y precisas bajo nuestro control. Al repasar los pilares que hemos construido, podemos ver una evolución clara:
En la Primera Parte (Visión y Fundamentos): Comprendimos cómo la IA utiliza la Visión Artificial y los Embeddings para traducir nuestra realidad (imágenes, textos, conceptos) a un lenguaje matemático. Establecimos que sin una buena base de datos y un entendimiento de cómo la IA «percibe», no podemos avanzar hacia la creación.
En la Creación Visual y Control (Pilares II y III): Vimos que generar contenido no es un acto de azar. Conceptos como Checkpoints, LoRA y ControlNet nos dan el poder de esculpir la creatividad con rigor técnico. Aprendimos que el Prompting (con técnicas como Chain of Thought o Negative Prompts) es en realidad una forma de programación en lenguaje natural que define el éxito de cualquier proyecto.
En la Arquitectura y Operaciones (Pilar IV): Finalmente, entendimos que la IA alcanza su máximo potencial cuando se especializa. El Fine-tuning y la Cuantización permiten que modelos masivos sean útiles y accesibles, mientras que los Agentes de IA marcan el inicio de una nueva era donde la tecnología no solo responde dudas, sino que resuelve problemas de principio a fin.
El Valor estratégico para el futuro
Dominar estos términos no es solo una cuestión de vocabulario; es adquirir el criterio técnico necesario para liderar en un mercado digital. Para un creador, emprendedor o investigador, entender la diferencia entre un Checkpoint y un LoRA, o saber cuándo aplicar un Chain of Thought, es lo que separa a un usuario casual de un profesional de la IA.
La IA generativa avanzada ya no se trata de «preguntar y esperar»; se trata de diseñar sistemas de pensamiento y ejecución que trabajen a nuestro favor.
Reflexión final: La IA no reemplaza el talento humano, pero lo potencia exponencialmente. Al conocer estas arquitecturas, pasamos de ser simples espectadores de la tecnología a ser los arquitectos de nuestras propias soluciones digitales.
¿Te resultó útil?, aquí más glosarios:

IA Operativa 2026: Guía Definitiva de Automatización Avanzada

Glosario Maestro de IA Generativa: Guía Definitiva para usuarios de IA – Parte 1